저는 cs231n을 base로 들어서 자세한 내용까지 설명하지 않았습니다.
https://arxiv.org/abs/1409.4842
Going Deeper with Convolutions
We propose a deep convolutional neural network architecture codenamed "Inception", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The
arxiv.org
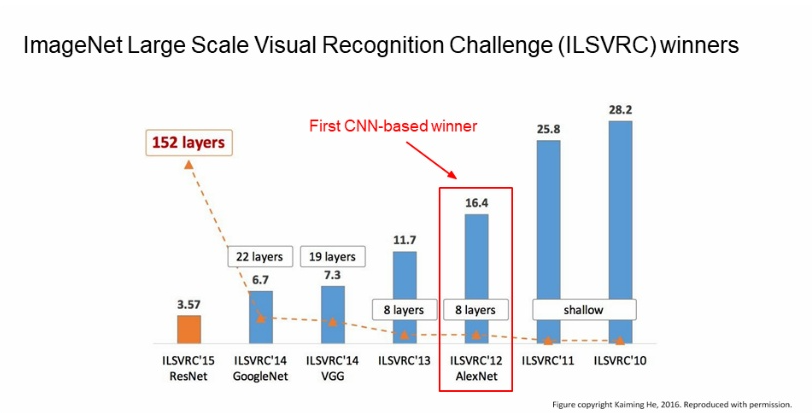
2014년에 GoogleNet은 ILSVRC 에서 우승 하였습니다.
Abstract
우리는 ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14) 에서 detection 과 classification 분야에서 새로운 deep convolutional neural network architecture를 제안 하는데 이름은 Incep-tion 입니다.
이 Architecture는network 내부의 Computing resources를 개선 합니다.
이는 네트워크의 depth와 width를 계산량을 유지하면서 늘리는 것이 목표 이며, 구조는 multi-scale processing과
Hebbian principle에 기초로 하였습니다.
GoogLeNet은 22개의 layer이다.
1 Introduction
지난 3년간 딥러닝보다는 Convolution network의 발전으로 인해서 image recognition과 object detection은 극적인
속도로 발전 하였습니다. 한가지 고무적인 것은 이러한 발전이 강력한 하드웨어와 큰 데이터셋, 그리고 큰 model 덕분이
아니라 새로운 아이디어, 그리고 개선된 알고리즘과 network architecture의 결과라는 것 입니다.
ILSVRC 2014에 제출한 GoogleNet은 2년전의 AlexNet보다 12배 적은 parameter를 사용하여 훨씬 정확한 결과를 얻을 수 있었습니다.
그리고 object detection의 큰 이점은 deep network와 아주 큰 model에서 오는 것이 아니라 R-CNN 같이
deep architecture와 고전적인 컴퓨터 비전의 시너지에서 오게 됩니다.
그리고 mobile및 embedded 컴퓨팅이 지속적으로 발전하여 알고리즘의 효율성, 그리고 메모리 사용의 중요성이 커지고
있으며, 주목할만한 것은 이 논문에서는 deep architecture의 설계에서 고려된 사항이 정확도 숫자에 집착 보다는 효율적인 계산, 메모리 사용량에 대한 것이 포함됩니다.
실제로 이거는 추론시간에 1.5billion 이하의 연산만을 수행하도록 설계 되었다고 합니다.
이 모델이 순수한 학문적 호기심이 아니라 대규모 데이터셋에서도 잘 사용되었으면 한다고 합니다.
이 논문에서는 컴퓨터 비전 분야에서 효율적인 deep CNN architecture인 inception에 focus를 맞춥니다.
이 아키텍처는 유명한 “we need to go deeper” 라는 인터넷 밈과 관련하여서 연구진이 네트워크 이름을 정했습니다.
2 Related Work
LeNet-5 를 시작으로 CNN은 일반적으로 하나이상의 Fully-connected layer이 뒤에 오는 Stacked convolutional layer를 가지게 됩니다.
이 기본적인 설계의 변형은 image-classification 분야에 넓게 퍼짐, MNIST에서 최고의 결과가 나왔습니다.
CIFAR, 특히 ImageNet classification같은 것은 대규모 데이터셋이므로 최근 추세는 layer 수와 layer의 size를 늘리고
있으며, overfitting 문제를 해결하기 위해서 dropout을 사용 하였습니다.
그리고 maxpooling layer가 spatial information의 손상을 초래 한다는 우려에도 불구하고, 동일한 CNN 이 localization,
object detection, human pose estimation 분야에서 성공적으로 채택 되었습니다.
Inception model이 여러번 반복되는 GoogLeNet model의 경우 22-layer의 deep model입니다.
object detecion은 이 당시에 가장 좋은 접근 방식은 R-CNN으로 R-CNN의 경우 Detecion을 위해서 두가지 하위 문제로
분해하는데, 먼저 color와 subpixel의 일관성과 같은 low-level의 단서를 이용하여 object proposal를 하고, CNN을 이용
하여서 해당 위치의 object의 category를 정하게 됩니다. 이러한 접근 방식은 low-level의 단서로 bbox를 분할의 정확성,
그리고 CNN의 매우 강력한 object classification 성능을 결합하는 것 입니다.
3 Motivation and High Level Considerations
deep neural networks는 성능을 향상시키는 것은 크기를 늘리는 것이라고 합니다.
여기서 network의 depth와 width의 증가도 포함됩니다.
특히 아주 많은 양의 lable된 train data를 사용 할 수 있다는 점 덕분에 higher quality model를 쉽고, 안전하게 훈련
가능 합니다. 하지만 여기서는 두개의 단점이 존재합니다.

크기가 클수록 일반적으로 parameter의 수가 많아서 특히 train set의 labeled된 예제 수가 제한 된 경우에는 network가
overfitting되기 쉽습니다.
그리고 high-quality의 training set을 만드는것 상당히 까다롭고, 비쌉니다.
그리고 ImageNet과 같이 세분화된 영역에서는 이러한 것이 문제가 될 수 있습니다.
그리고 크기가 uniformly 하게 증가된 network는 computational resource가 엄청나게 증가합니다.
예를들면 deep vision network에서 만약 두개의 convolutional layer가 결합하면 filter 수가 균일하게 증가하여 계산량이 2배가 증가 합니다.
만약 추가된 capacity가 ( 가중치가 0에 가까운 경우) 많은 계산량이 낭비 됩니다.
실제로 할 수 있는 계산량을 유한하여, 주요 목적이 결과의 quality를 좋게 하기 위해선 크기보다는 계산 resources를
효율적으로 분배하는 것이 좋습니다.

이러한 문제를 해결하는 방법은 fully connected된 것에서 sparsely connected architecutre로 바꾸는 것 입니다.
심지어 convolution 내부에서도 이렇게 바꿉니다.
생물학적 시스템을 보고 따라한것 이외에도, 획기적인 연구로 인해서 단단한 이론적 토대가 될 수 있습니다.
어떤 연구에서는 주요 dataset의 probability distribution이 크고 spared deep neural network에 표현 될 수 있는 경우,
last later의 activation correlation statics를 분석하고, 상관관계가 높은 출력을 가진 neuron을 clustering 하여 최적의
network toplogy를 얻을 수 있다고 합니다. 수학적 증명이 필요합니다.
이 아이디어는 less strict한 조건에서도 적용이 가능합니다.
단점으로는, 오늘날의 Computing infrastructure는 non-uniform sparse data structure의 numerical calculation에 매우 비효율적 입니다.
arithmetic operations 100배 감소 하더라도, lookup와 cache miss는 매우 우세하여, sparse matrics로 전환하면 좋은
성과를 얻기는 힘들어집니다.
기본적인 CPU또는 GPU Hardware 의 아주 작은 detatil을 활용하여서 매우 빠른 dense matrix multiplication을 허용하고
개선된 라이브러를 활용함으로써 계속에서 격차가 벌어지게 됩니다.
또한 non-uniform sparse model은 정교한 engineering괴 computing infrastrucutre가 필요합니다.
대부분의 vision oriented machine learning systems은 단지 convolution layer를 이용하는 것 만으로 spatial space을
활용합니다.
Convolution은 이전 layer의 patches의 dense connection으로 구성 됩니다.
ConvNet은 보통 대칭성를 깨고, train을 개선하기 위해서 기능 차원에서 무작위 및 spare 연결 table을 이용 하였지만,
optimize parallel computing를 개선하기 위해서 fully connected로 변경 되었습니다.
structure의 uniformity와 많은 수의 filter, 더 큰 batch크기를 이용하여서 효율적으로 dense computation을 이용 할 수 있습니다.
Spares matrix 연산을 다루는 문제는 Sparse matrix를 클러스터링 하여 Dense한 Submatrix를 만드는 것을 제한 했고
괜찮다고 하였습니다.
GoogleNet의 저자들은 Inception 구조는 Sparse구조를 test하기 위해 시작했는데, hyperparameter를 조정하고 한 결과
꽤 좋은 성과가 나왔습니다.
4 Architectural Details

Inception architecture의 주요 idea는 convolution vision network의 optimal local sparse structure를 찾는 쉽게 구할 수
있는 dense가 높은 components로 근사하고 커버가 가능한 방법을 찾는것을 base로 합니다.
translation invariance를 가정 한 뒤에 network의 convolution building block을 구축 하다는 것을 의미합니다.
여기서 필요 한 것은 optimal local construction을 찾아서 spatially으로 반복 하는 것 입니다.
Arora는 마지막 계층에서 correlation 를 분석하여 correlation 가 높은 단위 group으로 cluster를해야 하는 layer-by-layer 를 제안 합니다. .. 주저리 주저리 말이 많은데 별로 안 중요한거 같네요.
이러한 inception module은 서로 stacked되는데, output의 correlation staristics는 달라질 수 밖에 없습니다.
즉 이러한 higher abstraction의 features이 higher layer의 captured됨에 따라서 spatial concentration이 감소 할 것으로
예상이 되어 3x3 및 5x5 convolution의 비율이 높아져야 합니다.
이러한 형태의 module은 큰 문제가 있는데, filter수가 많은 convolution layer 위에서 5x5 convolution layer을 사용하면
엄청나게 계산량이 많아 집니다. 이 문제는 pooling unit이 mix에 추가 되면 더욱더 심해집니다.
output fliter의 수는 previous stage의 filter수와 같습니다.
pooling layer의 output과 convolution layer의 output이 병합하면 stage 간 output의 수가 매우 증가합니다.
이러한 구조는 계산량이 폭발하게 됩니다.
이는 두번째 아이디어로 이어집니다.
즉 계산 요구사항이 지나치게 증가 하는 것을 막기 위해서 dimension reductions and projection을 적용합니다.
이는 embeddings의 성공에 기반하며, 저차원 embedding에도 상대적으로 큰 image patch에 대한 많은 정보가 포함
가능합니다. 그러나 embedding은 information 밀도가 높고 압축된 것은 모델링하기 어렵습니다.
그러므로 1x1 convolution은 계산량이 많은 3x3 , 5x5 convolution 을 계산하기 위해서 사용합니다.
이는 reductions효과 뿐만 아니라 Rectified linear activation의 사용을 포함하므로 dual-purpose입니다.
최종 결과는 b입니다.
일반적으로 inception network는 위와 같은 module들이 stack이 된 형태이며, grid resolution을 줄이기 위해서 stride가
2인 max pooling layer가 가끔 존재합니다.
train 중에 메모리 효율성으로 인해, 낮은 layer들은 기존의 convolution 벙식을 유지, 높은 layer들은 inception moduel을 사용 하였습니다.
이 디자인은 실질적으로 유용한 측명이 있는데 다양한 시각정보를 다양한 규모로 처리 한 뒤에 통합하여야 한다는 직관
과 일치합니다.
이 디자인은 계산량이 상당히 조절되어 어려움 없이 width와 depth 를 늘릴 수 있습니다.
inception을 활용하는 다른 방안은 안좋지만 계산적으로 더 저렴한 것을 만드는 것 입니다.
5 GoogLeNet
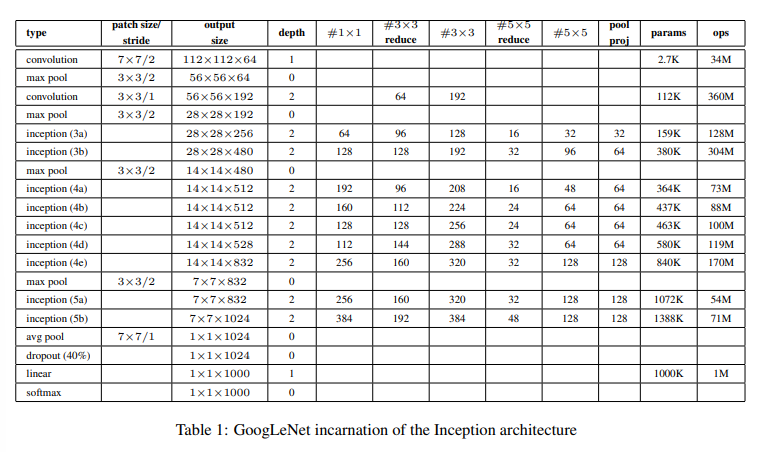
이 사람들은 ILSVRC14 대회에서 GoogLeNet이라는 팀 이름을 선택, 이것은 LeNet5 네트워크를 개척한 LeKun에게 경의
를 표하는 것 이라고 하네요. 앙상블 하여서 제출 하였습니다.
inception modules 내부를 포함한 모든 Convolution layer은 ReLU를 사용합니다.
Network의 receptive field는 224x224로 RGB channel의 평균으로 subtraction합니다.
3x3 reduce와 5x5 reduce는 3x3 및 5x5 convolution 이전에 사용 된 reduction layer의 filter 수를 나타냅니다.
maxpooling 후 projection layer에서 1x1 filter 수를 볼 수 있습니다.
layer를 변경된 rectified linear activation도 사용 합니다.
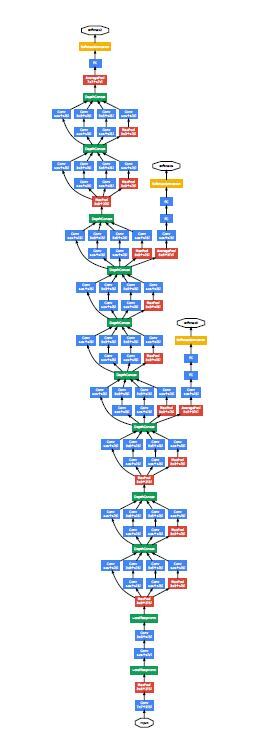
network는 계산의 효율성, 그리고 실용성을 염두하고 설계 하였으며, 메모리 공간의 적은 계산 자원을 이용하여
inference가 되도록 하였습니다.
parameter거 있는 layer만 셀 경우 depth는 22, pooling까지 세면 27개 입니다.
network에 사용되는 전체 layer는 100개 입니다.
network가 depth가 깊어지면 gradient를 효과적으로 모든 layer에 전파 할 수 있는 능력이 중요합니다.
이것은 중간 layer에 보조 분류기를 추가 하여, 하위 단계에서 gradient signal를 증가시키며, 추가적인 regularzation을
증가 시킵니다.
inference시간에는 보조 network 없어집니다.
보조 분류기는 다음과 같습니다.
5x5 filter 크기에 stride 3인 average pooling layer로 , 출력은 4x4x512 입니다. (4a)의 경우, (4d)의 경우 4x4x528입니다.
dimension reduction 및 ReLU를 위한 128 개의 1x1 convolution filter
1024개의 unit과 ReLU 로 연결된 FC layer.
dropout layer, 70%
classifier은 softmas 입니다.(1000개의 class inference시간에는 사라짐)
Conclusions
Inception 구조는 Spares structure을 Dense Structure로 근사 성능을 개선.
기존에 cs231n으로 이미 본 model이였는데, 대충 몇개 이해안되는 부분이 있었지만 , 1x1 conv, 보조 분류기를
이용하여 계산량을 낮추고, graident 가 사라지는 현상을 방지하여 deep 하고 wide한 모델을 만든거 같음.
아이디어가 매우좋다.
논문보면서 직감대로 해석한거라 틀린부분도 있습니다.