주관적인리뷰 이므로 틀린내용이 무조건 존재
https://arxiv.org/abs/1909.13719
RandAugment: Practical automated data augmentation with a reduced search space
Recent work has shown that data augmentation has the potential to significantly improve the generalization of deep learning models. Recently, automated augmentation strategies have led to state-of-the-art results in image classification and object detectio
arxiv.org
RandAugment Paper Review
논문 링크 : https://arxiv.org/abs/1909.13719
Abstract, Introduction
data augmentation은 model의 **generalization(일반화)**을 크게 개선한다. 특히 image classification(분류), object detection(객체탐지) 등 다양한 분야에서 모델 성능 개선에 큰 도움이 된다는 것이 밝혀졌다.
하지만 이러한 Data augmentation은 어려움이 존재한다.
- data augmentation을 적용할려는 domain마다 가지고 있는 데이터셋의 특성이 다름.
- 그러므로 domain에 **prior knowledge(사전지식)**을 알고 augmentation policy(증강정책) 선택.
- 하지만 이러한 prior knowledge를 찾는 것은 어렵고 별도의 Search space가 필요.
- 그리고 만약 prior knowledge를 찾더라도 다른 domain으로 확대하는 것은 매우 어려움.
이러한 문제를 해결하기 위해 최근 data augmentation policy를 딥러닝을 통해 찾기 시작하였다.
- NAS에서 최적의 Network 아키텍처를 찾는 것 처럼 data augmentation에서도 최적의 policy를 찾을려고 노력 하는 것.
- train된 data augmentation policy로 ML model을 학습하는 것은 정확도를 올려주는 경향이 존재.
- 하지만 data augmentation policy와 ML model 각각 training 하는 것은 계산량이 많음.
- 특히 두개의 분리된 최적화 절차를 수행하는 것은 어려움.
최근에는 PBA, Fast autoaugment에서 효율적인 방식을 제시 하였지만 여전히 문제가 존재한다.
- 기존에 존재하던 문제와 마찬가지로 여전히 분리된 최적화 절차가 필요함.
- 그리고 작은 데이터셋 학습한 data augmentation policy가 큰 경우에도 적용된다고 가정.
- 하지만 작은 데이터셋에서 학습한 것을 큰 데이터셋에 그대로 적용하는 것은 문제가 존재.
- 문제가 발생한 다는 것은 본 논문에서 실험을 통해 보여줌.
- augmentation을 적용하는 정도는 모델, 데이터셋 사이즈에 의존한다는 것을 확인 가능.
그러므로 본 논문에서는 위에 결과물들을 참고하여 RandAugment를 고안하였고 대략적인 특징은 다음과 같다.
- Search space를 낮추기 위해 별도의 Proxy task를 제거, 아주작은 연산량으로 적용이 가능.
- Proxy task를 없애고 Augmentation 을 적용 하여도 성능이 좋거나 비슷함.

위 Table을 확인하면 개략적인 성능을 알 수 있다.
- CIFAR-10, SVHN, ImageNet 데이터셋.
- PyramidNet, Wide-ResNet-28-10, ResNet-50, EfficientNet-B7 모델.
- AutoAugment, Fast AutoAugment, Population Base Augmentation, RandAugment 사용.
- Search Space가 10^2 이지만, 4개의 Case에서 동등하거나 좋은 성능을 보임.
2. Related Works
Data augmentation은 deep vision model을 train할때 자주 사용되었다.
- natural image에서 horizontal flip, random cropping, translation 등 은 일반적으로 자주사용.
- horizontal flip은 이미지를 좌우반전 시키는 것.
- random cropping은 이미지의 일부분을 취득하는 것.
- translation은 이미지를 이동시키는 것.
- 등등 다양한 이미지 처리 연산이 존재한다. 너무 많은 연산이 존재하므로 일부만 소개.
- MNIST 에서는 scale, position에 elastic distortions 적용하여 인상적인 결과를 얻었다.
- Elastic distortions은 Scale과 Position에 왜곡을 주는 것.

MNIST Elastic Distortion을 적용 한 것.
- 이전의 예시에서는 트레이닝 데이터셋의 분포를 유지한 채로 증가 시켰다. 그러므로 수행하는 연산은 일반화를 늘리는데 효과적이다. 일부 방법들은 validation accuracy, robustness 또는 둘다 향상을 시키기 위해서 무작위로 영상
에서 patch를 지우거나, noise를 추가하였다. - Mixup은 CIFAR-10과 ImageNet에서 특히 효과적인 augmentation방법이다.
- 여기서 network는 이미지와 그에 대응되는 label의 조합에 대해 훈련을 진행.
MixUp 방식으로 다음과 같이 두개의 이미지를 조합하는 annotation 방법

- Object-centric cropping은 일반적으로 object detection tasks에서 사용. cut-and-paste로 train image에 새로운 object image를 추가한다.
Cut and Paste를 이용하여 기존 Real Image에 학습 한 것.

위의 data augmentation 방식들을 제외하고도 data를 확장하는 작업은 다른 것과 결합하기 위한 최적의 전략을 찾는데 초점을 맞추고 있다.
- 예를 들면 Smart Augmentation의 경우에는 동일한 class의 두개의 sample을 병합하여 새로운 data를 생성하는 network를 train
- Tran이라는 연구자는 train 세트에서 학습한 distribution을 바탕으로 베이지안 접근방식으로 data augmentation을 수행.
- DeVries는 data를 증가시키기 위해 **noise, interpolation(보간), extrapolations(외삽)**를 수행.
- GAN을 이용하여 data augmentation을 수행.

data로 부터 data augmentation 전략을 학습하는 또 다른 접근방식은 AutoAugment로 강화학습 을 이용하여 sequence of operation과 적용 확률 및 규모를 선택함. 위 그림은 sub-policy가 적용될 확률 및 크기
- AutoAugment policy 적용에는 여러가지 확률 적용. 다음과 같은 절차를 거쳐서 적용한다.
- 모든 minibatch의 모든 이미지에 대해 uniform probability로 sub-policy가 선택.
- 각 sub-policy에서의 동작에는 확률이 있음.
- 일부 연산은 방향에 대한 확률을 가진다.
- 예를 들면 이미지를 시계방향이나 시계반대 방향으로 회전
- 확률을 이용하여 network훈련되는 다양성을 증가 시키고, 이는 많은 데이터셋에서 generalization을 크게 개선
PBA나 Fast Autoaugment는 autoaugment에서 더 좋은 방법을 찾기 위해 노력한 결과물이다.
- 시간은 줄어들었지만 별도의 search phase가 있어서 문제.
- 이 논문에서는 별도의 proxy task에서 search phase를 제거하는 것을 목표로함
3. Methods
RandAugment의 목표는 proxy task에서 별도의 search phase가 필요하지 않도록 하는것.
- proxy task란 본래의 목적을 달성하기 위한 부가적인 task를 말함.
- Search phase를 없앨려는 이유는 별도의 search phase가 training을 복잡하게됨.
- 그리고 계산량이 많아지는 안좋은 현상이 존재.
- 그리고 proxy task가 꼭 최선의 결과를 얻는것도 아님!!.
이전에 augmentation 방법들은 30개 이상의 하이퍼파라미터를 포함 해야했음.
- 저자들은 parameter space을 크게 줄이는데 초점을 맞춤.

변환 적용 확률을 열거한 것.
- 이전 연구에서는 다음과 같이 변환중에 변환을 선택하고 각 변환을 적용할 확률을 열거함.
그러면 RandAugment에서는 어떤 parameter만을 사용하느냐?
- 첫번째 parameter로는 augmentation을 적용할 변환의 개수(N), 논문에서는 14개 선택.
- parameter space를 줄이면서 이미지의 다양성을 유지하기 위해 각 변환을 적용하는 확률은 균일한 확률인 1/K.

저자들이 적용한 변환의 종류 총 14개
- Training image에 N개이 변환이 주어지면 RandAugment의 경우에는 K^N개의 정책을 선택할 수 있음.
- 그리고 마지막 Parameter는 distortion(왜곡)의 크기(M)
- 왜곡의 크기란 그림으로 이해하는게 더 쉬움

Figure1. Example RandAugment
- 위 의 그림은 보면 N = 2 이고, M은 한줄씩 9,17,28를 적용한 예 값이 커질수록 그림의 왜곡이 심해지는 것을 알 수 있다. 논문에서는 0~10 사이로 M을 정한다고 합니다.

- 저자들은 M을 선택하는 방식을 여러개로 구분하여 Test Random, Constant, Linear Increasing, Random Magnitude로 Test 성능이 0.1% 정도 거의 차이가 나지 않는 다는 것을 알 수 있다.

- 알고리즘은 다음과 같이 아주 간단한 파이썬 코드로 구현가능하다.

Python Based Numpy 구현
- 코드가 매우 간단하며 인간이 해석하기 편하고 N,M이 커질수록 regularization strength이 커짐 ( Data가 더욱더 다양해 지므로)
- N,M을 선택하기 위해 다른방법도 선택 할 수 있지만 저자들이 개발한 것은 매우 작은 search space를 고려할 때 naive grid search가 효과적이라고 함. Grid search (격자 탐색) 은 모델 하이퍼 파라미터에 넣을 수 있는 값들을 순차적으로 입력한뒤에 가장 높은 성능을 보이는 하이퍼 파라미터들을 찾는 탐색 방법이다.
4. Results
본 논문에서는 small proxy task에서 data augmentation policy를 찾는것이 문제라고함 모델 사이즈와 data set 사이즈가 두가지 측면에서 이를 분석함

- 그림을 보면 왼쪽위를 보면 distortion magnitude에 따른 성능을 확인 할 수 있음.
- 사각형이 표시 된 것이 최적의 Magnitude인것을 암시함.
- network size가 클수록 큰 distortion Magnitude에서 좋은 성능을 보임.
- 위의 결과로 알 수 있는 것은 small proxy task에서 distortion Magnitude 찾는것은 부적절함
- 왼쪽 밑에 그림은 widening, 네트워크 사이즈에 따른 결과임.
- Parameter가 커질 수록 distortion 이 커져야 성능이 좋아지는 것을 알 수 있음.
- 오른쪽은 training data set 사이즈 에 대한 결과임.
- 확인하면 **1k인 파란색에서는 3%**정도. 4k인 것은 2%, **10k인 것은 약 1.5%**만 성능이 좋아짐.
- 오른쪽 아래를 보면 data set의 사이즈가 클수록 optimal distortion magnitude가 커짐.
- 이는 작은 data set에서 더 큰 Regularization이 필요할거 같다는 예상과는 일치안함
- 이 결과는 중요한 점이 있음. 더 큰 data set에서는 더 강한 augmentation이 필요함. 일부만으로 파악하는 proxy task에는 문제가 있음. proxy task에서 한 policy는 전체 training data에는 적용하기 안좋은 것을 알 수 있음.
CIFAR와 SVHN에서 결과
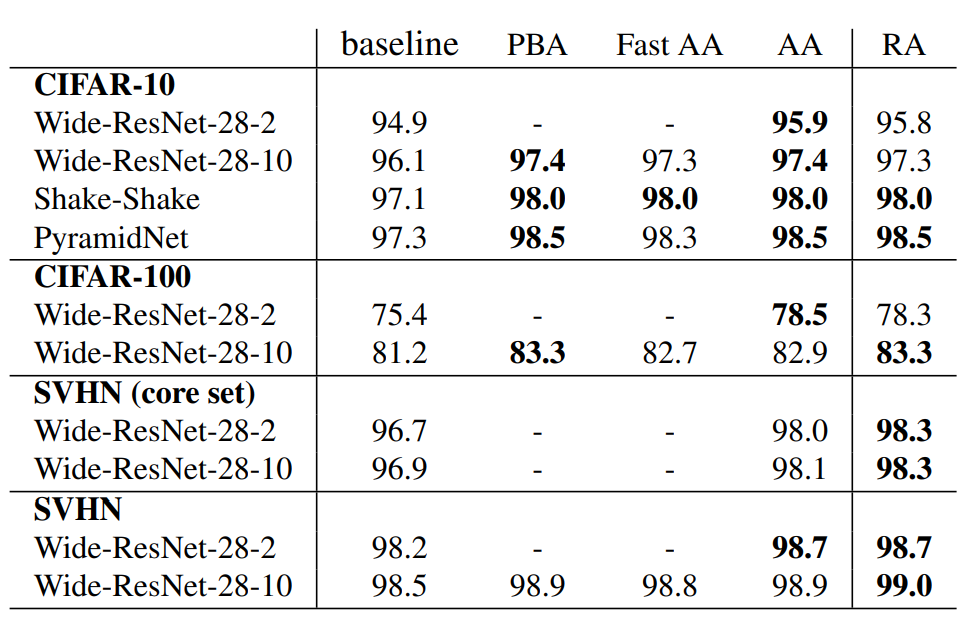
- CIFAR , SVHN에서 결과는 다음과 같다.
- RA는 PBA, FAST AA, AA에 비해 성능이 꿀리지 않고, 몇몇은 제일 좋은 것을 알 수 있음.
- CIFAR와 SVHN은 아예다른 이미지를 가지고 있음. Fast AA나 ,AA에서의 Policy는 많이 다른 결과가 나왔다고 한다.
- 즉 data augmentation policy 가 많이 달라도 RandAugment는 동일 또는 더 좋은 성능이 나오게 된다는 것을 알 수 있음.
IMAGENET에서 결과

- 모델에서 성능을 개선하는 data augmentation이 항상 imagenet과 같은 데이터셋에서 성능을 좋게 하는 것은 아님.
- 항상 성능을 향상시키는게 아니거나 거의 변화가 없었다.
COCO에서 결과
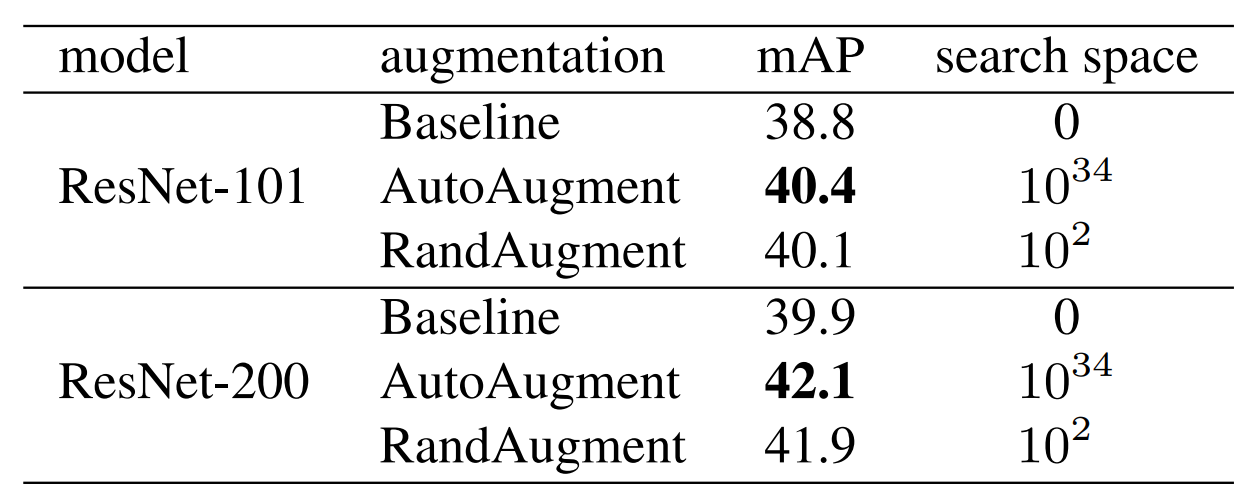
- object detection은 다음과 같은 결과가 나온 것을 알 수 있다.
- Auto augment에서는 randAugment에서 사용하지 않은 변환도 사용하도록 하였다.
- 그리고 굉장히 큰 Search space, GPU연산량이 들어도 6개의 value의 하이퍼 파라미터 튜닝한 RandAugment와 비슷한 결과가 나온 것을 알 수 있다.
- 이 실험에서는 RandAugment가 bbox에서도 적용가능한 transformation이 제한되어 있어 더 다양한 변환이 필요하다고 함.
변환 개수에 따른 결과
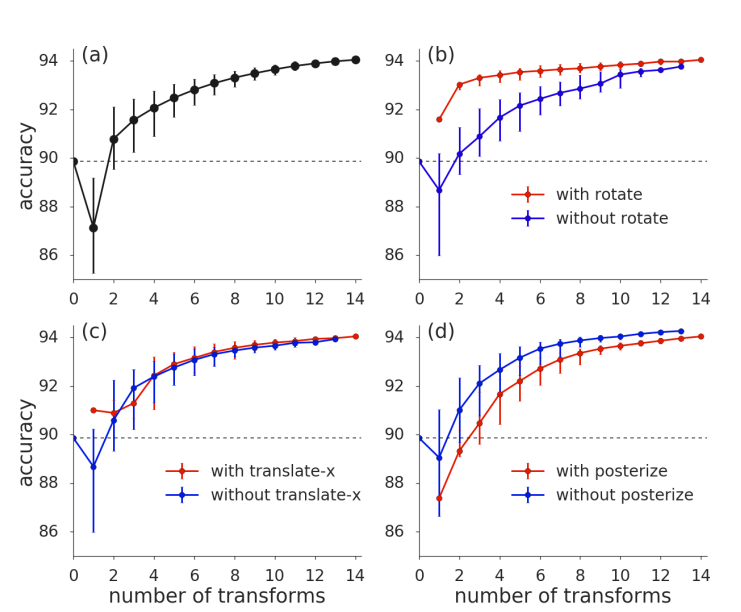
모든 결과는 CIFAR-10 기준이다.
- (A)
- 그래프 A를 보면 변환이 많으면 성능이 높아짐.
- (B)
- 그래프 B를 보면 rotate가 성능에 큰 영향을 미친 다는 것을 알 수 있음.
- (C)
- 그래프 C를 보면 translate는 생각보다 큰 영향을 미치지 않는 것을 알 수 있음.
- (D)
- 그래프 D를 보면 poseterize는 성능이 안좋아지는 것을 알 수 있음. (이미지 음영을 조절하는것,아래 그림은 poseterize의 결과)

다른 결과
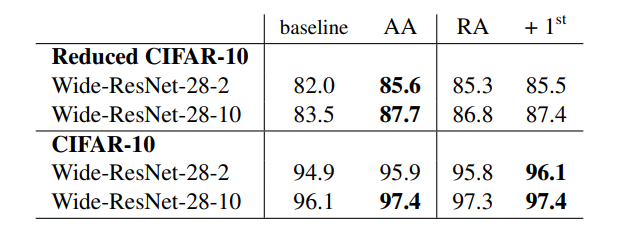
- 위의 결과는 확률을 학습하면 성능이 좋아진다고 생각했으며, 작은 data set에서 테스트를 한 것.성능이 향상된것을 확인할 수 있었으며, 큰 data set에 대해선 차후 과제로 남겨두었습니다.
5. Discussion
- data augmentation은 최고의 성능을 위해 필수
- 학습된 data augmentation 전략을 자동화 하여 성능을 높임
- 별도의 search 없이 기존연구와 비슷하거나 좋은 성능을 얻음
- 기존의 연구는 큰 data set에서는 적용이 힘들지만 두개의 hyperparameter를 이용하여 좋은 성능을 얻음
Using RandAugment
Unofficial Pytorch Reimplementation of RandAugment 카카오 브레인 김일두
GitHub - ildoonet/pytorch-randaugment: Unofficial PyTorch Reimplementation of RandAugment.
GitHub - ildoonet/pytorch-randaugment: Unofficial PyTorch Reimplementation of RandAugment.
Unofficial PyTorch Reimplementation of RandAugment. - GitHub - ildoonet/pytorch-randaugment: Unofficial PyTorch Reimplementation of RandAugment.
github.com
RandAugment가 구현된 부분은 다음과 같다.
pytorch-randaugment/augmentations.py at master · ildoonet/pytorch-randaugment
GitHub - ildoonet/pytorch-randaugment: Unofficial PyTorch Reimplementation of RandAugment.
Unofficial PyTorch Reimplementation of RandAugment. - GitHub - ildoonet/pytorch-randaugment: Unofficial PyTorch Reimplementation of RandAugment.
github.com
Python Imaging Library를 이용하여 구현
pip install git+https://github.com/ildoonet/pytorch-randaugment
명령어를 입력하여 설치 가능.
from torchvision.transforms import transforms
from RandAugment import RandAugment
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(_CIFAR_MEAN, _CIFAR_STD),
])
# Add RandAugment with N, M(hyperparameter)
transform_train.transforms.insert(0, RandAugment(N, M))
다음과 같이 transform에 N,M Hyperparameter를 조절하여 insert한다.
RandAugment.ipynb
Colaboratory notebook
colab.research.google.com
'AI 공부 한 것' 카테고리의 다른 글
| [백준 23288] 주사위 굴리기 2 (Python) (0) | 2022.06.30 |
|---|---|
| [논문 리뷰] Transformer (Attention Is All You Need) (0) | 2022.06.21 |
| [논문 구현] ResNet (2015) 논문구현 (Deep Residual Learning for Image Recognition) (0) | 2022.01.30 |
| [논문 리뷰] ResNet (2015) 논문리뷰 (Deep Residual Learning for Image Recognition) (0) | 2022.01.28 |
| [논문 구현] inception v1, GoogLeNet(2014) 논문구현 (Going Deeper with Convolutions) (0) | 2022.01.22 |