https://arxiv.org/abs/2103.14030
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as
arxiv.org
Abstract
- General Purpose Backbone으로 Computer Vision 분야에 이용가능한 Swin-Transformer를 제안
- Transformer는 기존에 NLP에서 생겨낫는데 이를 Vision에 적용할때 Domain의 차이, Text에 비해 Token의 개수가 많아지는 고해상도 이미지라는 문제가 존재
- 이런 문제를 해결하고자 Shifted Window로 계산되는 Transformer를 제안
- Shfited Window는 Self-Attention을 Non-Overlapping Local Window로 제한하고, Cross-Window 연결을 허용하여 Efficiency를 향상시킴
- 이런 계층구조는 다양한 규모로 Modeling 가능한 유연성을 가지고, Image Size에 관련해서 Linear Computatioanl을 가지게 됨
- 이런 방식으로 Vision Backbone을 요구하는 Task에서 SOTA에 달성
Introduction
- CNN은 Computer Vision 분야에 지배적이고, ImageNet 대회에서 훌륭한 성공을 얻었음
- Great Scale, Extensive Connection, 정교한 구조까지 다양한 Field에서 발전함
- 반면에 NLP 분야에서는 다른 방향으로 발전하였고, Transformer라는 아키텍처가 가장 유명함
- Transduction Task에서는 Sequence Modeling이 필요하고, Transformer는 Long-Range Depedencies를 Attention을 이용해 잘 Capture
- 이런 NLP에서 성공을 보고 Vision에서도 이를 적용하기 위해 노력
- 본 논문에서는 Transformer가 NLP 및 CNN이 비전에서 하는 것 처럼 Computer Vision을 위한 General Purpose Backbone 역활을 할 수 있도록 가능성을 확장
- 해당 저자들은 NLP영역에서 높은 성능을 Vision영역에 이식하는데 두가지 Modalities 차이가 존재
- 하나는 Scale, NLP Transformer는 처리의 기본 요소로 Word Token을 이용하지만 Visual Element는 크기가 다양함
이는 Object Detection(객체의 크기, 이를 극복하기 위해 FPN이라는 것이 CNN에 존재)에서 발생하는 문제임. Swin 이전에 Transformer는 모두 Fixed Scale이며 이는 Vision Application에서는 적합하지 않음 - 두번째는 Text에 비해 Image의 해상도가 너무 높다는 문제, Pixel 수준의 Dense Prediction을 필요로 하는 Semantic Segmentation 같은 Task에서는 이용하기 어려움, Transformer의 Big-O는 Token의 개수의 Quadratic

- 이런 문제를 해결하기 위해 General Purpose Backbone인 Swin Transformer를 제안, Hierarchical Feature Map을 구성하고, Image Size에 대해서 Linear Complexity를 가짐
- 그림의 (a)처럼 Swin Transformer는 Small Size Patch(회색 테두리)에서 시작, 깊어지는 Transformer에서 인접 Patch를 Merge하며 Hierarchical Feature Representation을 생성
- 이런 Hierarchical Feature Map을 이용해서 FPN, U-Net과 같은 Dense Prediction Task를 위한 Advanced Techniques를 이용 가능
- Linear Complexity은 빨간색 테두리로 표시된 Non-OverLapping 내에서 Local로 Self-Attention을 진행하므로 가능함
- 각 창의 Patch의 수는 Fixed이므로 Complexity는 Image Size에 종속됨
- 이러한 장점으로 다양한 Vision Task의 Backbone으로 이용 가능하고, 기존의 Single Resolution Feature Map을 만드는 ViT에 비해 유용
- Swin Transformer의 Key Design은 Shift of Window Partition Between Consecutive Self-Attention Layer
- Window 내의 모든 Query Patch는 동일한 Key Set을 공유하므로 Memory Access에 용이함
- Sliding Window기법글은 매번 서로 다른 Query Pixel에 대한 서로 다른 Key Set을 이용하므로 느
- Shfited Window는 이전 Layer의 Window를 Bridge하여 Modeling 성능 향상
- Sliding Window보다 빠른 속도, 낮은 지연시간을 가짐
Related Work
- CNN은 Deeper, Effective Convolution 방식으로 진화, VGG, GoogleNet, ResNet Etc.. Backbone으로 유용함
- Self-Attention Base의 NLP 성공으로 영감을 받은 Vision 연구자들은 ResNet을 대체하기 위해 노력, 하지만 기존 CNN에 비해 Memory Cost도 높음
- CNN과 Transformer를 붙이는 DETR같은 Task도 존재
- 여러 시도가 있었지만, Dense Prediction Task에서 이용하기 위해서는 여러 해상도의 Feature Map이 필요, 그러므로 Swin Transformer가 이를 해결
Method
- Swin Transformer Tiny 시각화
- 처음으로 Input RGB image가 들어오면 Non-OverLapping Patch로 Split(ViT 방식) 각 Patch는 Token
- 저자들은 4 x 4 Patch를 이용하여 각 Patch의 Feature Dimension은 4 x 4 x 3 = 48이됨
- 그 뒤에 Linear Embedding Layer를 통과시켜 차원 C로 Projection H / 4 x W / 4 x 48 -> H / 4 x W / 4 x C
- 이후에 Transformer Block에서는 Token의 개수를 유지하며 진행됨(Stage 1 , H / 4 x W / 4 Token)
- Hierarchical Representation을 위해 Patch Merging Layer를 이용해 병합, Token수 감소
- 첫 Patch Merge에서는 인접한 2x2 Patch에 대해 각 Group의 Feature로 연결, 4C 차원으로 깊어진 Feature에 대해서 Linear Projection을 적용(2C)
- 이 방식은 Token의 개수를 4배 줄임( H / 4 * W / 4 -> H / 8 * W / 8) 이것을 Stage 3, 4에 반복
- VGGNet, ResNet 과 비슷한 동작방식으로 Backbone으로 이용 가능
- Swin Transformer는 두개의 연속된 Swin Transformer구조는 W-MSA, MLP, SW-MSA, MLP 구조를 가지게 됨
- Standard Transformer는 Global Self-Attention을 진행, Global Attention은 계산량이 Token의 개수에 대해 Quadratic, 이는 Token이 많은 Vision에 적합 x
- Self-Attention in Non-Overlapped Window : 효율적인 Modeling을 위해 Local Window내에서 Self-Attention을 계산 할 것을 제안
- Window들은 Non-Overlapping 되는 방식으로 Image를 균일하게 분할
- 각 Window에 M x M Patch가 포함되어 있다고 가정하면, 계산량은 아래와 같고, W-MSA 방식이 훨씬 가벼운 것을 알 수 있음
- Shifted window partitioning in successive blocks : Window-Base Self-Attention Module에서는 다른 Window간의 Connection이 부족함
- Non-Overlapping Window의 효율적인 계산을 유지하며, Cross-Window Connection을 도입하기 위해 Consecutive Swin Transformer Block에서 두개의 방법을 오가며 진행하는 것을 제안
- Figure2 처럼 첫 Module은 일반적인 Window내의 8 x 8 Feature Map은 4 x 4의 , 즉 2x2개의 Window로 나누어져서 Window내에서 Self Attention을 취함
- 그 뒤에 Window크기의 절반만큼 오른쪽 아래 방향으로 Shift하여 Self-Attention을 진행
- Shifted Window Partitioning 접근법으로 다양한 Task에서 효과적
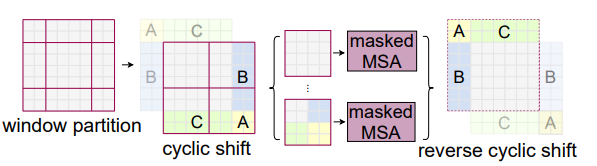
- Efficient batch computation for shifted configuration : Window를 Shift시키면 기존 [h / M] X [w / M] 에서
[h / M + 1] X [w / M + 1]이 됨, 그리고 몇몇 Window는 M x M보다 작게됨(Patch Size보다) - Navie Solution은 작은 창을 M x M 크기로 Padding하는것, 이런 방식은 2x2 -> 3x3 계산량이 2.25베 증가
- Cyclic Shift 방식을 이용하여 다시 2x2 Window Self-Attention을 취함
- 하지만 이때 Masking을 이용하여 같은 Partition내에 있는 Window에 대해서만 Attention이 진행되도록 함
- 결국 4개의 Window에서 Attention Score Map을 구하고, 자기와 같은 구역에 있는 Patch들에 대해서만 Score를 살리고, Masking 하는 방법을 이용

- Related Position Bias : Swin Transformer는 Self-Attention을 진행할 때 Relative Position Bias를 이용
- 기존에는 Position Embedding을 절대좌표를 이용했지만 방법을 바꿈
- B ∈ R(M^2×M^2), Q, K, V ∈ R(M^2×d), M^2은 Window 내의 Patch의 개수
- Patch 들간의 상대위치를 넣어주며 절대 위치보다는 Object들의 Part를 파악하기 쉬움
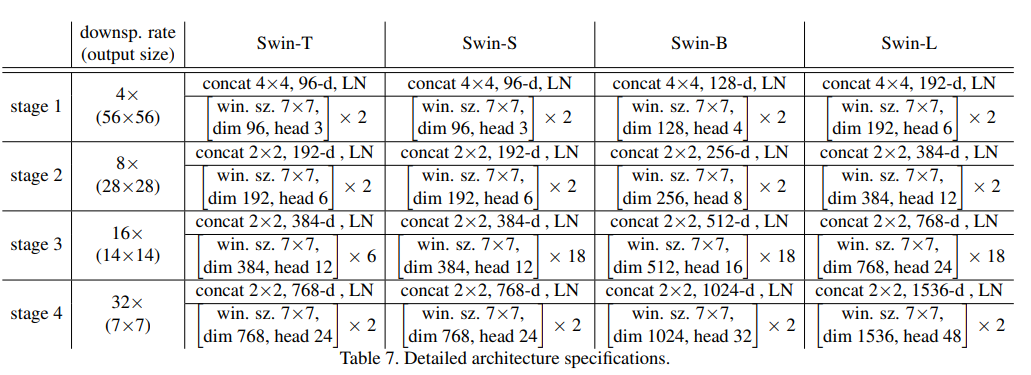
- Model Detail : 총 4개의 Version이 존재
Experiments
- ImageNet 1k Classificaton, COCO, ADE20K, 3개에서 SOTA달성
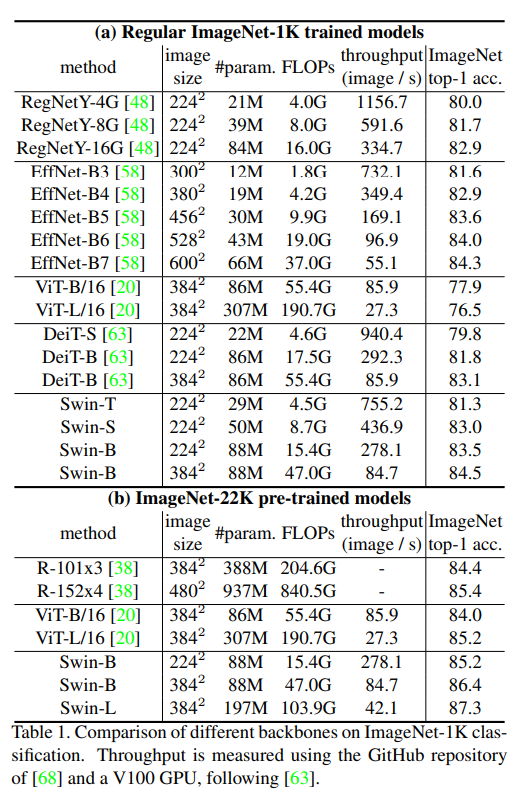
- Image Classification on ImageNet-1K
- 첫번째는 Pretraining하지 않고 진행한 결과, ViT Base 보다 Parameter가 적고, EfficientNet가 비슷한 결과를 얻음
- 두번째는 ImageNet 22k로 Pretraining, ImageNet-1k로 Fine Tuning, ViT Model과 비슷한 처리속도를 가진 Swin-B는 훨씬 높은 정확도를 얻음
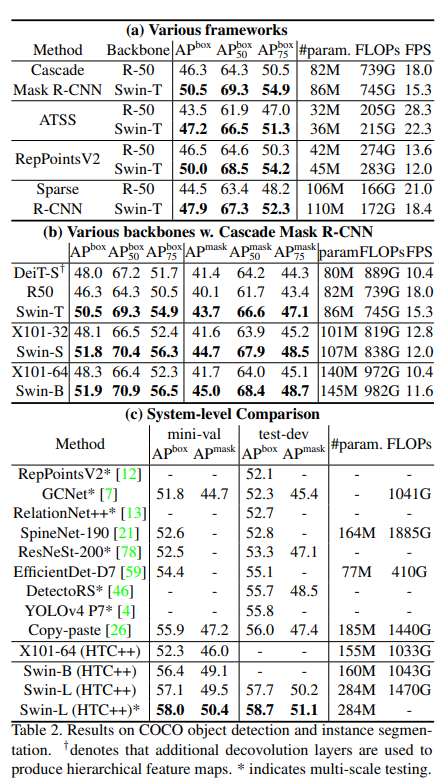
- Object Detection on COCO
- (a) ImageNet 21k Pretraining, 비슷한 Parameter, FLOPs를 가지는 ResNet을 이용, FLOPs 상승, FPS는 감소 했지만 모든 경우에 좋은 성능을 얻음
- (b) Csacade Mask R-CNN에서 다양한 Backbone을 이용하여 Instance Segmentation, 모든 경우에 Swin이 좋음
- (c) HTC에서 비교한 결과 모든 SWIN Model이 좋은 결과를 얻음, ResNet은 고도로 최적화된 Cudnn을 이용하지만, 일반적인 Pytorch를 이용해 ResNet보다는 최적화가 덜 된 상태에서도 비슷한 연산, 더 높은 결과. SOTA달성
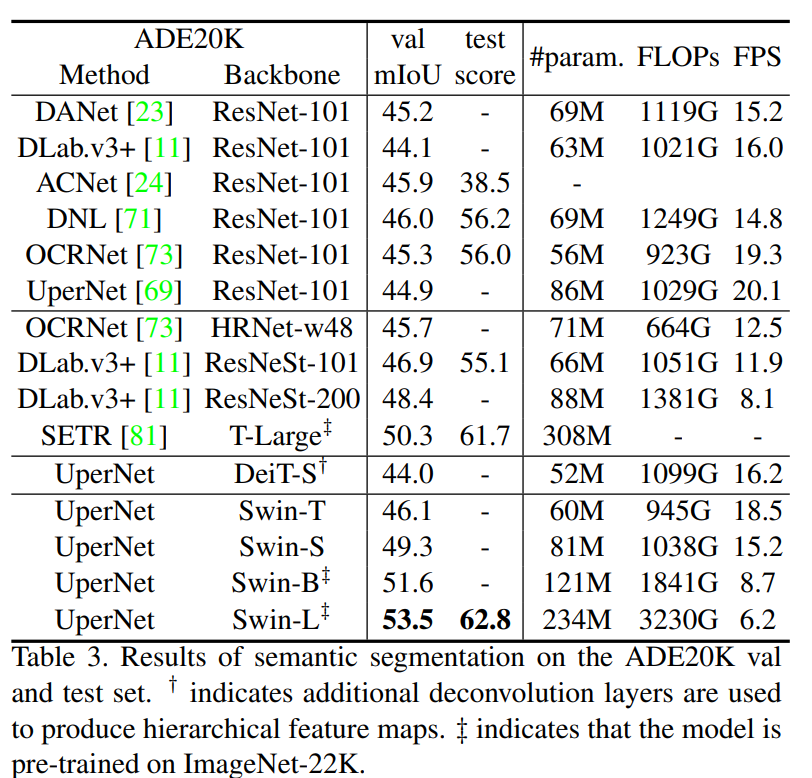
- Semantic Segmentation on ADE20K
- Swin Backbone이 좋은 결과를 얻음, 낮은 FLOPs & Parameter
Ablation Study
- 각 Design Element를 조사함
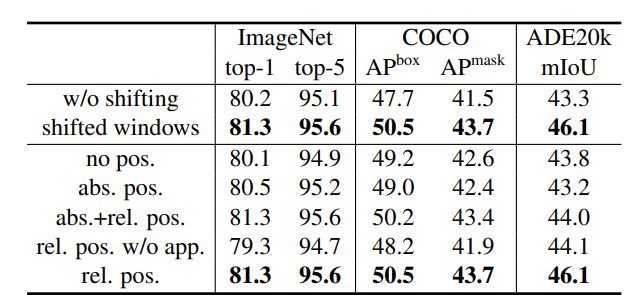
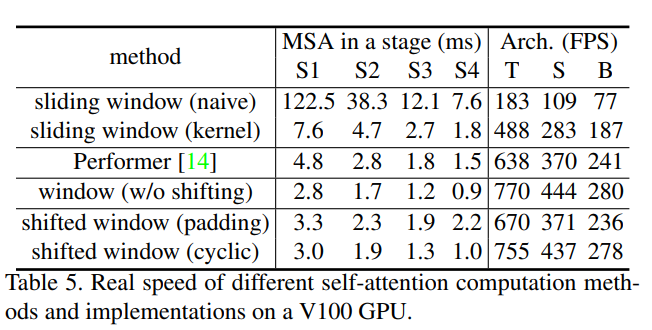
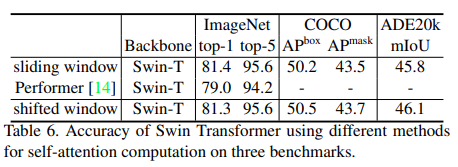
- Table 4에서 Shfited Window방식이 좋은 결과를 얻음, Table5를 봐도 Shfited Window는 적은Overhead를 가짐
- Relative Position Bias가 있는 경우 제일 좋은 결과, ViT/DeiT는 Visual Modeling에서 오랫동안 중요한 것으로 자리잡은 Translation Invariance를 포기 했지만, Translation Invariance를 장려하는 Inductive Bias가 여전히 Dense Prediction Task에서 선호되는 것을 확인(상대위치)
- Self-Attention 기법에서 Shfited Window Cyclic이 효율적인 것을 알 수 있음, T, S, B에모두 빠른 속도를 보여줌
- 또한 정확도 또한 Shifed Window방식이 좋음
'AI 공부 한 것' 카테고리의 다른 글
| [논문 리뷰] TubeViT [Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning] (2) | 2023.03.10 |
|---|---|
| [논문 리뷰] Video Swin Transformer (0) | 2023.02.27 |
| [논문 리뷰] ViT (AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE) (0) | 2023.02.07 |
| [후기] KT AI석사과정 계약학과, 한양대 AI응용학과 합격 후기 (52) | 2022.12.26 |
| [백준 23291] 어항 정리 (Python) (0) | 2022.07.02 |