How ChatGPT actually works
Since its release, the public has been playing with ChatGPT and seeing what it can do, but how does ChatGPT actually work? While the details of its inner workings have not been published, we can piece together its functioning principles from recent researc
www.assemblyai.com
How ChatGPT Actually Works
ChatGPT는 OpenAI의 최신언어 Model이며 이전 GPT-3에 비해 개선 됨
제작자들은 Supervised LR, Reinforcement LR사용하여 Fine Tuning했지만, ChatGPT를 강하게 만든것은 RLHF(Reinforcement Learning from Human Feedback)
사람 Feedback 사용해서 harmful, Untruthful, Biased Output을 최소화
RLHF가 어떻게 이용되는지, GPT-3의 한계가 뭔지 그 훈련과정에서 어떻게 파생되는지 조사 해야함
Capability vs Alignment in Large Language Models
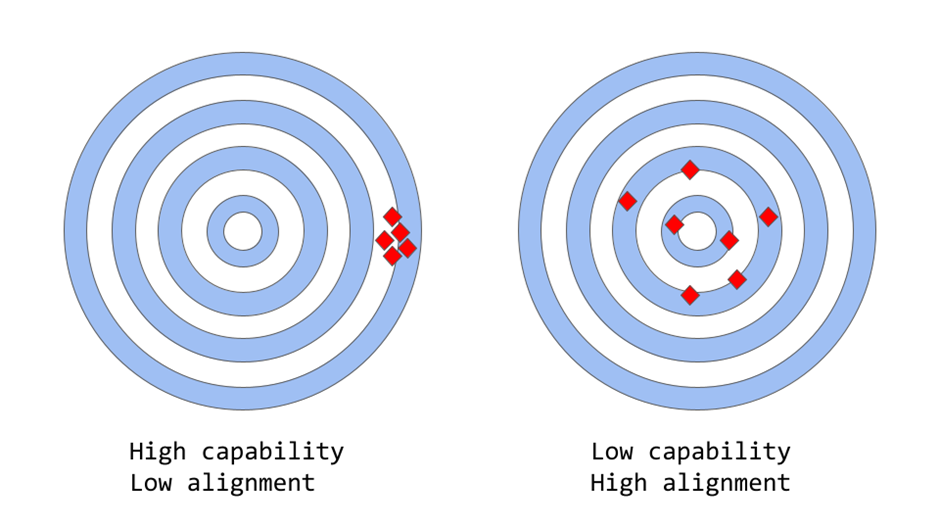
Capability : 특정 Task 또는 일련의 Task를 수행하는 Model의 기능을 나타냄
Model의 Capability는 Model의 목표를 정의하는 수학적 표현인 Objective Function을 얼마나 잘 최적화 될 수 있는지에 따라 평가됨
Ex 주식 시장 가격을 예측하도록 설계된 모델에는 모델 예측의 정확도를 측정하는 Objective Function이 있을 수 있음
모델이 시간 경과에 따른 주가의 움직임을 정확하게 예측할 수 있다면 이 작업에 대한 높은 수준의 Capability을 가진 것
Alignment : Alignment는 Model이 실제로 수행하기를 원하는 것과 Model이 수행하도록 Training되는 것과 관련이 있음
한마디로 "그 Objective Function이 우리의 의도와 일치하는가?"라는 질문을 던지는 것
즉 Model의 목표와 행동이 인간의 가치와 기대에 부합하는 정도를 나타냄
Ex 새를 분류하는 Model이 있다면 Log Loss Function으로 학습시에 Model의 Log Loss는 낮아지지만, 실제 Test에서 Classification에서는 정확도가 낮음. 즉 Model의 Capability는
GPT 3같은 경우 Model이 Misaligned됨
GPT3와 같이 Large-Scale Language Model은 Internet의 방대한 양의 Text Data에 대해 교육받고, 인간과 유사한 Text를 생성해도, 인간의 기대, 또는 바람직한 값과 일치하는 Output을 생성안함, Aligment가 낮음
실제로 그들의 Objective Function은 Word Sequence(or Token Sequence)에 대한 확률분포로 Sequence에서 다음 단어가 무엇인지 예측하는 것 (Language Modeling)
그러나 실제 Application에서 이러한 Model은 어떤 형태의 가치 있는 인지작업을 수생하기 위한 것 이며, 모델이 훈련되는 방식과 우리가 사용하고자 하는 방식 사이에는 차이가 존재
Word Sequence에서 Machine Calculated Statistical Distribution이 수학적으로 보면 Language Modelding 하는데 매우 효과적인 선택처럼 보이지만, 인간으로서 우리는 배경지식과 상식을 사용하여 주어진 상황에 가장 적합한 Text Sequence를 선택하여 언어를 생성
이는 Language Model은 지능형 개인 비서와 같이 높은 수준이 필요한 경우에는 문제됨
엄청난 양의 Data에 대해 훈련된 강력하고 복잡한 Model은 지난 몇년 동안 유능해졌지만, 인간의 삶을 더 쉽게하기에는 단점이 존재
Lack of helpfulness : 사용자의 명시적인 지시를 따르지 않음
Hallucinations : 존재하지 않거나 잘못된 사실을 만드는 모델
Lack of interpretability : 인간이 모델이 특정 결정이나 예측에 도달한 방법을 이해하기 어려움
Generating biased or toxic output : Biased/Toxic Data에 대해 Training 된 언어모델은 명시적으로 지시하지 않은 경우에도 출력이 나올수도 있음
이런 Alignment문제를 해결하기 위해 좋은 Training 방식은 뭘까?
how language model training strategies can produce misalignment?
Next-token-prediction & masked-language-modeling은 Transformer와 같은 Language Modeling Training에 사용되는 핵심기술
Next-token-prediction
첫 번째 접근 방식에서 Model은 일련의 Word(또는 "Tokens", 즉 parts of words)를 Input으로 받고 시퀀스의 다음 단어를 예측하도록 요청. 예를 들어 모델에 입력 문장이 주어진 경우
"The cat sat on the"
이렇게 나오면 이전 Context에서 이러한 Word가 나타날 가능성이 높기 때문에 다음 단어 "mat", "chair", "floor"를 예측할 수 잇음, Language Model은 실제로 주어진 Previous Sequence에서 가능한 각 단어의 likelihood(가능성)을
masked-language-modeling
Masked-Language-Modeling은 Input Sentence의 일부 Word가 [MASK[와 같은 특수 Token으로 대체되는데 Next-Token Prediction의 변형임
Mask된 대신 삽입해야하는 올바른 단어를 예측하도록 Model에게 요청
"The [MASK] sat on the"
입력으로 다음 단어를 "cat", "dog" 또는 "rabbit"로 예측할 수 있음
이런 Objective Function은 한가지 장점은 Model이 일반적인 Word Sequence 및 Word 사용 Pattern과 같은 Language의 Statistical Structure을 학습 가능
이는 일반적인 Model보다 자연스럽게 유창한 Text를 생성하는데 도움이 됨. 모든 LM Model의 Pretraining 단계에서 필수
이러한 Objective Function의 문제를 일으킬 수도 있음. 본질적으로 Model이 중요한 Error와 중요하지 않은 Error를 구별할 수 없음
아주 간단한 예를 들자면 다음과 같음
"The Roman Empire [MASK] with the reign of Augustus."
'Began', 'End'를 모두 예측이 가능하고, 두 단어 모두 발생 Likelihood가 매우 높기 때문에(두 문장 모두 역사적으로 정확함)
선택이 가능, 하지만 두개는 매우 다른 의미를 가지고 있음
보다 일반적으로 생각하면, 이러한 Training전략은 Text Sequence에서 다음 Word(Masking 단어)를 예측하도록만 Training된 Model이 반드시 일부를 학습하지 않을수도 있기 때문에 일부 더 복자한 Task에 대한 언어모델의 Alignment가 잘안됨
결과적으로 Model은 언어에 대한 더 깊은 이해가 필요한 작업이나 Context로 일반화하는데 어려움을 겪음
OpenAI의 연구원과 개발자는 Large-Scale Language Model의 Alignment 문제를 해결하기 위해 다양한 접근방식을 연구
Chatgpt는 원래 GPT-3 Model을 기반으로 하지만 Model의 Alignment 문제를 완화한다는 특정 Objective로 학습 Process로 진행하기 위해 Human Feedback을 사용하여 추가로 Training
이 테크닉의 이름은 Reinforcement Learning from Human Feedback 이전 학술 연구를 기반으로 함
ChatGPT는 프로덕션에 투입된 모델에 대해 이 기술을 사용한 첫 번째 사례를 나타냅니다.
근데 Chatgpt의 제작자들은 Human Feedback을 정확히 어떻게 사용하여 Alignment문제를 해결하나?
Reinforcement Learning from Human Feedback
해당 방식은 전반적으로 3가지 단계로 구성됨
1. Supervised Fine Tuning Step : Pre-Trained Language Model은 라벨러가 선별한 상대적으로 적은 양의 Demo Data에서 Fine Tuning 되어 선택한 Prompts list에서 Output을 생성하는 Supervised Policy(SFT)를 학습
이는 Baseline Model을 나타냄
2. “Mimic human preferences” Step : 라벨러는 상대적으로 많은 수의 SFT Model의 Output에 투표하도록 요청받고, 이렇게 하면 비교 데이터로 구성된 새 Dataset이 생성됨. 그 뒤에 이 데이터셋에서 Model이 학습됨. 이를 RM(Reward Model)이라고 함
3. Proximal Policy Optimization (PPO) step : Reward Model은 SFT Model을 더욱 Fine Tuning 하고 개선하는데 사용됨.
이 단계의 결과는 Policy Model임
각 단계의 세부사항을 살펴보면 다음과 같음
(참고: 이 문서의 나머지 부분은 InstructGPT 논문의 내용을 기반으로 합니다. OpenAI에 따르면 ChatGPT는 "InstructGPT와 동일한 방법을 사용하지만 데이터 수집 설정에 약간의 차이가 있습니다" 을 말함. 아쉽게도 ChatGPT에 대한 정확한 보고서는 아직 공개안됨)
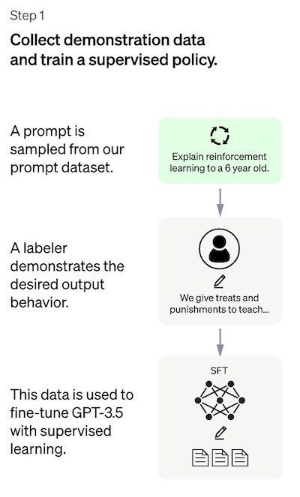
Step 1 : The Supervised Fine-Tuning (SFT) model
첫 번째 단계는 SFT Model라고하는 Supervised Policy Model을 Training하기 위해 Demo Data를 수집
Data Collection : Prompts List가 선택되고 Labeling 작업자 Group이 예상되는 Output Response를 기록하도록 요청받음.
ChatGPT의 경우 두 가지 Prompts Source가 사용되었음.
일부는 라벨러 도는 개발자가 직접준비했고, 일부는 OpenAI의 API Response(GPT-3 고객)에서 Sampling
이 전체 Process는 느리고 비용이 많이 들기 때문에 Pre-Train된 언어모델을 Fine Tuning하는데 사용되는 상대적으로 작고 고품질의 선별된 데이터셋이 생성(12~15k Data Point)
Choice Model : 원래 GPT-3 Model을 Fine Tuning하는 대신 ChatGPT 개발자는 소위 GPT- 3.5 시리즈의 Pre-trained된 Model을 선택함.
아마도 사용된 Base Model은 대부분 Programming Code에서 Fine Tuning된 GPT-3 Model인 text-davinci-003일것임
따라서 흥미롭게도 개발자는 ChatGPT와 같은 범용챗봇을 만들기 위해 순수 Text Model이 아님
'개인연구메모' 카테고리의 다른 글
| [TimeSformer, Something-Something v2 설치] (0) | 2023.05.07 |
|---|