https://arxiv.org/abs/1409.1556
Very Deep Convolutional Networks for Large-Scale Image Recognition
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x
arxiv.org
논문 링크 입니다.

VGG-16은 ILSVRC에서 2014년에 TOP-5 error rate가 7.3%가 나온 아주 우수한 model로 대표적인 연구 입니다.
ABSTRACT
이 논문에서는 Convolution netwokr 의 Depth가 Large-Scale image recognition 설정에서 미치는 영향을 조사 합니다.
그리고 이 논문에서는 3*3 convolution filter를 가진 netwrok architecture을 이용하여 depth를 증가시켜 평가합니다.
그리고 network의 깊이를 16-19 weight layer로 하면서 이전의 기술보다 더 좋아졌습니다.
ImageNet Challange 2014에 출품 하였는데, localisation and classification tracks에서 각각 1위와 2위를 하였습니다.
그리고 컴퓨터 비전에 추가 연구에 용이하게 하기 위해 두가지 ConvNet 모델을 공개 하였습니다.
INTRODUCTION
ConvNets은 최근 large-scale and video recognition에서 큰 성공을 거두고 있습니다.
이는 2009년 ImageNet과 대규모 공공 이미지 덕분에 가능해 졌고, GPU와 large-scale distribute cluster같은 것들이 있어서 성공적으로 가능 하였습니다.
그리고 deep visual recognition architectures의 발전에 중요한 역활은 ILSVRC에 의해서 수행이 되었습니다.
이미지 분류 시스템의 Testbed 같은 곳 입니다.
ConvNets는 컴퓨터 비전 분야에서 더욱 상품화 됨에 따라 AlexNet의 연구를 더욱 개선 할려고 하였습니다.
그 결과 13년에 우승한 작품은 AlexNet에서 조금만 변경 하였습니다.(파라미터나 층 구조)
또 다른 쪽에서는 전체 이미지와 Multiple scales의 걸쳐 network를 조밀하게 훈련하고 테스트 하였습니다.
이 논문에서는 ConvNet architecture 설계에서 중요한 depth문제를 다루는데, 이를 위해서 architecture 의 다른
parameters를 수정하고 모든 layer에 매우 작은(3x3) convolutional layer를 추가하여 network의 depth를 높였습니다.
결과적으로 ILSVRC classification and localisation 높은 정확도, 그리고 단순한 Pipeline의 일부를 사용하더라도 우수한 성능을 달성하는 다른 이미지 인식 데이터셋에도 적용 가능합니다. (예를 들면 fine-tuning 없이 liear SVM으로 분류된
Deep feature)그리고 성능좋은 모델 두개를 공개 하였습니다.(VGG16,VGG19)
나머지 부분에 잘 정리 되어 있으며 , 2장은 ConvNet의 구성에 대해 설명, image classification training and evaluation 은 3장, 4장에는 ILSVRC Classification , 5장에서는 논문을 끝냅니다.
부록 A에서는 ILSVRC-2014 object localisation system를 설명, 부록 B는 dataset에 대한 generalisation읜 Discuss,그리고 부록C에는 주요 논문 목록을 담고 있습니다.
2 CONVNET CONFIGURATIONS
2.1 에서는 ConvNet의 일반적인 Configurations
2.2 에서는 ConvNet의 평가에 사용되는 특정 Configurations
2.3 에서는 자기들의 설계에 대해서 설명하고, 앞에 기술과 비교 합니다.
2.1 ARCHITECTURE
train 중에는 ConvNet의 대한 INPUT은 224*224 RGB Image로 고정 됩니다.
여기서 하는 data pre-processing은 오직 train set에서 계산한 mean RGB값을 빼는 것 뿐입니다.
Image는 Convolution layer를 통과 하며, 여기서 저자들은 아주 작은 Receptive filed를 사용 합니다.
(CNN에서 Receptive field는 각 단계의 입력 이미지에 대해 하나의 필터가 커버할 수 있는 이미지 영역의 일부를 뜻)
3 x 3을 이용하는데 좌우아래위 중앙을 capture하는 작은 크기 입니다.
그 중에는 input channel을 linear transformation 으로 볼 수 있는 1x1 convolution filter도 사용 합니다.
비선형은 뒤에서 처리합니다. Convolution stride는 1 pixel로 고정됩니다.
그리고 Conv layer에서 Spatial padding은 Convolution 이후에도 spatial resolution이 유지 됩니다.
즉 3x3 Convolution layer에 대해 padding을 1 입니다.
왜냐하면 (이미지 width/height - filter_size + padding*2) / stride + 1) 이기 때문입니다.
Spatial padding은 Max Pooling layer에 의해서 수행됩니다. 그리고 이 layer는 일부는 Convolution layer이후에 수행,
이때 Max pooling 은 stride는 2, 2x2 로 수행됩니다.
Convolution layer stack에는 그 이후에 3개의 Fully connected layer가 옵니다.
처음 두개는 4096개의 Channel, 세번째는 ILSVRC를 위해서 1000개의 Channel입니다.
Final layer는 softmax layer이며, Fully connected layer의 Configuration은 모두 동일합니다.
모든 Hidden layer는 ReLU가 non-linearity가 있습니다.
LRN , 저번에 AlexNet에서 사용한 방식은 사용하지 않습니다. 왜냐하면 Local Response Normalisation는 ILSVRC Dataset 의 성능을 향상 시키지는 않지만 Memory와 계산 시간을 증가 시킵니다.
2.2 CONFIGURATIONS
A-E 까지 이름을 정합니다.
모든 Configuration은 2.1에서 말한것에 의해 일반적인 설계를 가지게 됩니다. 깊이만 다릅니다.
11 weight layers in the network A (8 conv. and 3 FC layers)
19 weight layers in the network E (16 conv. and 3 FC layers)
Convolution layer의 Channel width는 작은 편으로, 첫 layer에서는 64, maxPooling layer마다 2배씩 증가하여 512.
표2에서는 각 Configuration 마다 Parameter수가 나옵니다. 원래는 엄청 많지만, 다른 것보다는 적네요.
2.3 DISCUSSION
VGG의 ConvNet 의 Configuration은 2012년 AlexNet과 2013년 우슨자의 Sermanet과는 다르게 되어 있습니다.
첫 Convolution layer는 large Receptive field, AlexNet의 경우 Stride 4, Stride를 사용하는 것에 비해 여기서는 모든
Network에 걸쳐서 매우 작은 3x3 Receptive filed를 사용합니다.
두개의 3x3 Convolution layer로 이루어진 Stack은 5x5 의 Receptive filed를 가지고 있습니다.
따라서 생각해보면 3x3 Convolution layer는 7x7 의 Receptive filed를 가지게 됩니다.
그러므로 하나의 7x7 layer를 사용하는 대신에 3x3 layer stack 을 사용하면 얻게 되는 장점은 무엇일까요?
첫째 3개의 Non linear rectification layer을 이용하여 decision function이 더욱 차별적으로 만듭니다.(좋게한다)
그리고 parameters의 수를 줄일 수 있습니다.
간단하게 3x3 Convolution stack 은 모두 C개의 채널로 구성되어 있다고 가정합니다.
3x3 Convolution layer stack 의 weight는 3 * (3*3*C*C) , 27*C^2 입니다.
7x7 Convolution layer의 경우 weight는 7*7*C^2, 49*C^2 입니다.
이로인해 약 3x3 Convolution filter를 이용하면 약 81%의 parameter를 줄일 수 있씁니다.
이것은 7x7 Convolution filter를 정규화 하는 것으로 볼 수 있으며 3x3 으로 분해합니다.
1x1 Convolution layer는 Convolution layer의 Receptive fields에 영향을 끼치지 않고 decision function의 non-linearlity
를 증가 시키는 방법입니다. 비록 1x1읜 입출력 채널의 수는 동일한 liear projection 이지만, 추가적으로 non-linearlity는
rectification 함수가 추가됩니다. 1x1은 Network in Network 아키텍처에서 사용 되었습니다.
Small size convolution filter는 이전에도 몇번 사용 되었습니다. 그러나 less deep 하고 ILSVRC Dataset에서 평가 하지 않았습니다. GoodFellow는 11 weight layer로 Street Number recongition 을 적용하였고, network의 depth가 깊어질수록 성능이 좋아지는 것을 알 수 있었습니다.
ILSVRC-2014 Classification에서 일등을 한 GoogLeNet에서는 VGG와 독립적으로 개발 하였지만, 매우 깊은 ConvNet(22weight layter)와 small convolution filter(3x3 과는 별도로 1x1, 5x5도 사용합니다.)를 기반으로 합니다.
Network topology는 VGG보다 복잡 하지만, 계산량을 줄이기 위해 첫 Layer에서는 Feature map의 resolution이 더
공격적으로 감소합니다. single-network classification accuracy에서 Szegedy보다 우수 합니다.
3 CLASSIFICATION FRAMEWORK
앞에서는 Network configuration에 대해서 설명 하였고, 이제 ConvNet Training 그리고 Evaluation에 대해 설명합니다.
3.1 TRAINING
ConvNet의 training procedure을 일반적으로 AlexNet을 다르게 됩니다.
(input crops from multi-scale training images 을 제외)
즉 여기서 training은 mini-batch gradient descent를 (역전파 기반)을 사용하며 mometum도 사용, multinomial logistic regression을 목표로 optimising 합니다.
batch size는 256, momemtum은 0.9입니다.
training regularised의 weight decay는 L2 penalty 5*10^(-4)와 , 첫 두 layer에 대한 drop out regularsation의 비율을 0.5
learning rate는 처음에는 1e-2 이지만 validation set의 accuracy가 좋아지지 않자 10배 감소 하도록 하였고, 총 train동안
3번 감소 하였습니다. 그리고 370K의 iteration후에 멈추었으며, 74epochs가 돌았습니다.
여기서 AlexNet 에 비해 더 많은 parameter와 , 더 큰 depth에도 불구하고, 더 큰 깊이, 그리고 더 작은 Convolution 크기에 의해서 암묵적으로 regularisation됩니다. 그리고 특정 layer의 pre-initialisation 덕분에 금방 수렴합니다.
네트워크의 weight의 initialisation은 중요합니다. 초기화가 잘못되면 deep network의 gradient 불안정성으로 인해
학습이 굉장히 오래 걸릴 수 있습니다.
이 문제를 피하기 위해서는 표1의 A를 random initialisation 할 수 있을 정도로 얕은 train부터 시작 하였고,그 다음
더 깊은 architecutres를 train 할때는 처음 4개의 Conv layer와 마지막 3개의 FC Later를 A Layer와 함께 초기화 .
(중간 layer는 무작위로 초기화) 여기서 미리 initialised된 layer는 learning rate를 줄이지 않고, train 중에 바꿀수 있도록 하였습니다.
random initalisation은 평균 0, 분산이 1e-2인 정규 분포에서 표본을 추출 하였고, bias는 0으로 하였습니다.
그리고 논문을 제출 한 다음에 Glorot & Bengjo의 random initialisation procedure을 통해 pre-train없이 초기화 가능 한
것을 찾았다고 합니다.
training image size는 isotropically rescaled을 하는데 이것의 의미는 training image의 넓이, 높이 중에 더 작은 width, height를 해당 사이즈로 줄이고, 이때 aspect ratio를 유지하여 rescale 합니다.
즉 해당 사이즈가 256이면, H = 1024, W= 512 이면 작은 길이를 가지는 W가 256으로 바뀌고, H는 512가 됩니다.
이때의 Scale하는 S값은 우리가 정해줍니다. 그리고 이 이미지에서 224x224만큼 Crop 합니다.
Crop의 크기가 224x224로 고정된 동안에는 원칙적으로는 s는 224이상의 값을 가져야 합니다.
여기서 Training Scale S를 설정하기 위해 두가지 방법으로 접근합니다.
single Scale training 이 방법은 S를 256 그리고 384로 고정시켜서 학습합니다. S를 256으로 학습 한 뒤에 그 다음으로 S를 384로 학습합니다. S=256으로 pre-train되어 있으므로 S=384로 할때는 Learning rate을 1e-3으로 낮춰서 학습합니다.
Second approach는 S를 multi-scale training 하는 것 입니다.
각 훈련 이미지는 [Smin, Smax]에서 random 하게 sampling 하여 scale을 조정합니다.(Smin = 256, Sma =512)
영상의 object size는 다를 수 있기 때문에 Train 중에는 이것을 고려 하는 것이 좋습니다.
이는 single model 이 크기가 다양한 범위의 object를 인식하도록 훈련하는 Scale jiittering 에 의한data augmentation 효과를 볼 수 있습니다. 속도상의 이유로 동일한 Configuration으로 single-scale model의 layer를 미세 조정 하여서 multi-scale model을 train 하였는데, S= 384로 Pre-train 하였습니다.
이것을 보통 scale jittering이라고 합니다.

3.2 TESTING
test에서는 ConvNet과 입력 이미지가 주어지면 다음과 같은 방식으로 합니다.
다양하게 Recale하여 입력으로 들어갔습니다. 다양하게 하는 덕분에 성능이 개선되었고, 또 Horizontal flipping를 하여 test set을 증가 시키고, 최종 점수를 얻기 위해서는 원본과 data augmentation 된 이미지들의 평균 점수를 이용합니다.
test image에서도 crop을 하였지만 비효율적 이라고 합니다.
3.3 IMPLEMENTATION DETAILS
여기서 구현은 Caffe을 이용 하였다고 합니다.
NVIDIA Titan Black GPU 4개를 이용하여 2~3주 걸렸습니다.
4개 사용해서 3.75배 빨라졌다고 합니다.
4 CLASSIFICATION EXPERIMENTS
dataset은 ILSCRC-2012 dataset을 이용합니다.
이거는 Train image는 130M, valid 는 50K, test는 100K를 사용합니다.
평가 기준은 top-1, top-5 두가치 척도를 이용하는데, top-1의 경우 예측이 잘못 된 경우, top-5는 predicte category에 없는 경우 입니다.
4.1 SINGLE SCALE EVALUATION

ConvNet model의 성능은 Single Scale로 평가 합니다.
test image size는 Q = S , jitter [Smin, Smax]의 경우 Q = 0.5(Smin + Smax) 로 설정합니다,
첫째는 LRN을 사용하는 모델 A에는 좋아지는 모습이 없었습니다. 그러므로 B ~ E에는 사용하지 않았습니다.
둘째는 Classification 오류는 ConvNet이 depth가 증가 할 수록 감소합니다.
A는 11개, E는 19개 Layer로 이루어 집니다.
특히 같은 depth에도 불구하고, C는 3개의 1x1 conv layer를 사용하는 것은, 네트워크 전체에 3x3 convv layer를 사용
하는 D보다 성능이 안좋습니다.
이는 추가적인 Non- linearity 에는 도움이 되긴 하지만,( C가 B보다 좋기 때문에) receptive field가 있는 것을 사용하는 것이 (D가 더 좋은거) 공간적인 맥락을 이해하는데 더 좋은거 같습니다.
아키텍처 Error rate는 depth가 19 layer에 도달하면 saturate됩니다. 더 깊은 model도, 더 큰 dataset도 도움이 될 수도 있습니다.
여기서 B와 5x5 conv layer을 가진 shallow network와 비교 하였는데, 이는 B에서 3x3 conv를 쓰는 것 보다 top-1 error rate가 7% 높다고 합니다.
마지막으로 single scale test 시간에 사용되더라도 train scale jittering 이 fix 된 것 보다 (S ≤ [256; 512]) 으로 하는게 더 좋은 결과가 나온 것 입니다. 한마디로 data augmentation이 잘 되었으므로 실제로 큰 도움이 된 것 입니다.
4.2 MULTI-SCALE EVALUATION
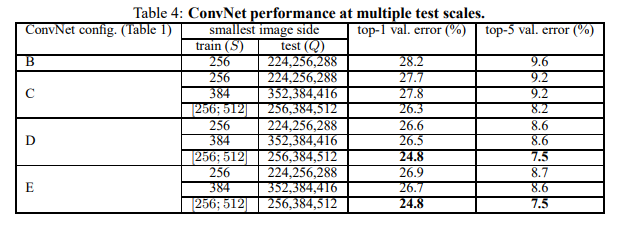
이제 Multi-scale 을 평가 하여 봅니다. scale jitter 효과를 평가 하는 것 이지요.
test 이미지의 여려 scale된 버전으러 model을 실행 하고 나서 class 의 posterior를 평균으로 구합니다.
train scale과 test scale의 큰 차이가 성능저하가 되는 것을 고려하여, 고정 S로 Train 한 model을 train image 크기에
가까운 test image size에 대해 평가 하였습니다.
Q = {S − 32, S, S + 32}
그리고 동시에 train 시에 scale jittering을 통해 된 것은 S s [Smin; Smax], Q = {Smin, 0.5(Smin + Smax), Smax} 에서
평가 하였습니다.
표 4에 결과를 보면 single-scale보다 multi scale도 좋은 결과가 나오는 것을 알 수 있습니다.
S를 고정하는 것 보다는 Scale jitter가 더 좋다는 것 입니다. 검증 세트에서 제일 좋은 것은24.8%/7.5% top-1/top-5.
그리고 Test set에서 TOP-5 error가 7.3% 입니다.
4.3 MULTI-CROP EVALUATION
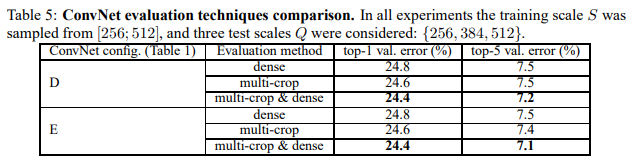
이 표는 dense가 높은 ConvNet 과 Multi crop 을 평가 및 비교 합니다.
softmax 출력은 두 평가 기법의 상호보완성을 평가하는데, 두가지 동시에 접근하는 방식이 상호보완적이라 좋습니다.
위에서 말한거와 같이 convolution boundary condition의 처리 때문 이라고 생각한다고 합니다.
4.4 CONVNET FUSION

지금까지는 개별 ConvNet에 model의 성능에 대해서 평가 하였습니다.
이 실험에서는 여러 모델의 softmax posteriors를 결합하여 평균화 합니다.
ILSVRC 제출 후에는 여기서는 dense eval을 통해여 7.0%를 ,dense multi-crop을 통하여 6.8%로 줄이는데 이때 두개의
최고성능 multi scale mode d,e만 앙상블을 하였습니다.
최고성능은 model E 입니다.
4.5 COMPARISON WITH THE STATE OF THE ART
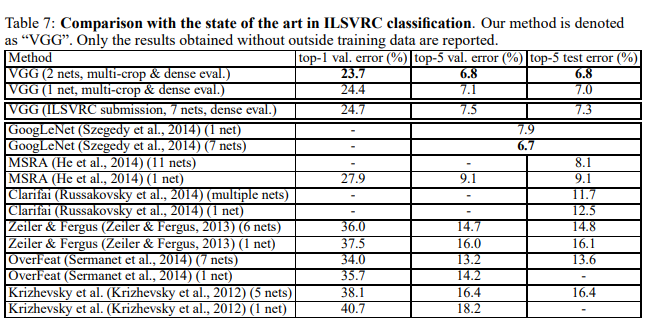
table 7은 다른 결과와 비교합니다.
VGG는 7개의 model과 앙상블 하여 7.3%로 2위를 하였습니다.
그리ㅗ 제출 한 뒤에 2개의 모델로 앙상블 하여 6.8%로 줄였습니다.
GoogLeNet와 비교해도 상당히 경쟁력이 있습니다.
그리고 흥미로운 것은 ILSVRC 에 제출한것과 달리 2개를 앙상블 한것 이 더 우수하다는 것 입니다.
단일 아키텍처 기준으로 자기들것이 0.9% 좋다고 합니다.
5 CONCLUSION
이 연구에서는 대규모 이미지 Classification을 위해서 deep convolutional network(19 weight layer)를 사용 하였습니다.
representation depth가 classification accuracy에 큰 도움이 되며, ImageNet 챌린지 데이터셋에 대한 좋은 성능 뿐만 아니라 ConvNet 아키텍처를 이용하여 달성 할 수 있다는 것이 입증되었습니다.
부록에서는 model이 광범위한 작업 및 dataset에 잘 일반화되어 deep image representation을 중심으로 구축된 복잡한 recognition pipeline과 거의 일치하거나 그 이상의 성능을 보여줬습니다.
여기서 visual representation은 depth의 중요성을 확인 해 줍니다.
GPU 빌려준 NVIDIA 감사합니다. 라고 하네여.
너무 기네요 논문 ㅜ
틀린 점 있으면 댓글 부탁 드립니다.
다음에는 논문을 구현하여 올리겠습니다.