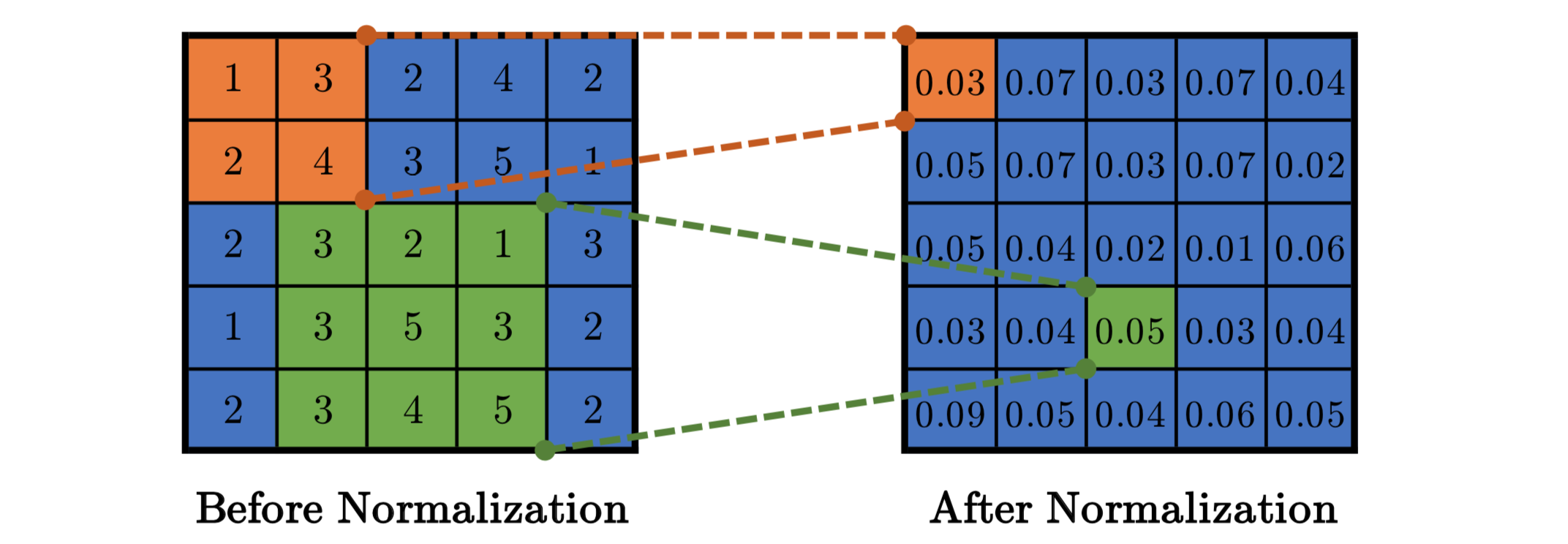
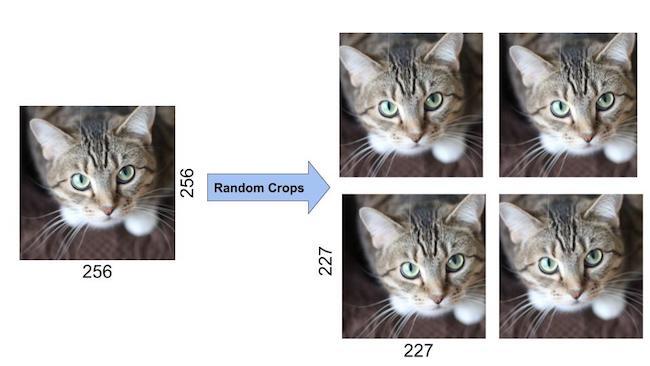
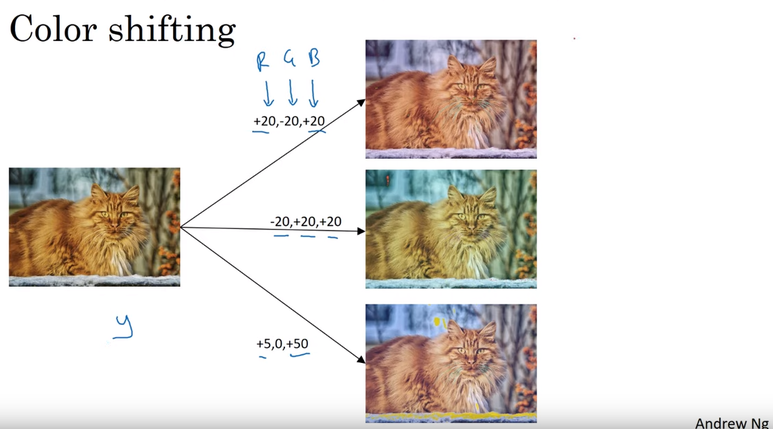
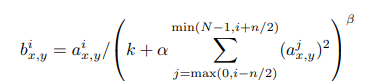https://inha-kim.tistory.com/41
[논문 리뷰] AlexNet(2012) 논문리뷰 (ImageNet Classification with Deep ConvolutionalNeural Networks)
https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf 오늘 review할 논문은 딥러닝의 시대를 열었다고 해도 되는 AlexNet입니다. AlexNet은 2012년 ILSVRC(ImageNet La..
inha-kim.tistory.com
논문 리뷰는 다음과 같이 하였습니다.
구현
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | class AlexNet(nn.Module): def __init__(self, num_classes = 1000): super().__init__() # INPUT 227*227*3 self.conv_layer = nn.Sequential( nn.Conv2d(in_channels=3,out_channels=96,kernel_size = 11, padding = 0, stride=4), nn.ReLU(inplace=True), nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2), nn.MaxPool2d(kernel_size=3,stride = 2), nn.Conv2d(in_channels=96,out_channels=256,kernel_size = 5, padding = 2, stride=1), nn.ReLU(inplace=True), nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2), nn.MaxPool2d(kernel_size=3,stride = 2), nn.Conv2d(in_channels=256,out_channels=384,kernel_size = 3, padding = 1, stride=1), nn.ReLU(inplace=True), nn.Conv2d(in_channels=384,out_channels=384,kernel_size = 3, padding = 1, stride=1), nn.ReLU(inplace=True), nn.Conv2d(in_channels=384,out_channels=256,kernel_size = 3, padding = 1, stride=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3,stride = 2) ) self.fc_layer = nn.Sequential( nn.Dropout(p=0.5,inplace=True), nn.Linear(in_features=(256*6*6), out_features=4096), nn.ReLU(inplace=True), nn.Dropout(p=0.5,inplace=True), nn.Linear(in_features=4096, out_features=4096), nn.ReLU(inplace=True), nn.Linear(in_features=4096,out_features=num_classes) ) self.init_weight_bias() def init_weight_bias(self): for layer in self.conv_layer: # Conv2D Layer check if isinstance(layer, nn.Conv2d): nn.init.normal_(layer.weight, mean = 0, std = 0.01) nn.init.constant_(layer.bias,0) nn.init.constant_(self.conv_layer[4].bias, 1) nn.init.constant_(self.conv_layer[10].bias, 1) nn.init.constant_(self.conv_layer[12].bias, 1) def forward(self,x): x = self.conv_layer(x) x = x.view(-1,256*6*6) return self.fc_layer(x) | cs |