https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
오늘 review할 논문은 딥러닝의 시대를 열었다고 해도 되는 AlexNet입니다.
AlexNet은 2012년 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge) 에서 우승하였습니다.
Abstract
ImageNet LSVRC-2010 대회에서 High resolution 이미지를 약 1000개의 다른 class로 분류 하기 위해
Deep Convolution neural network를 train 하였으며, test data에서 top-1 and top-5 error rates가 37.5% 및 17.5%를
달성 하였습니다. 이는 이전보다 발전한 상태입니다.
약 6천만개의 parameter와 65만개의 뉴런이 사용 됩니다. 그리고 5개의 convolutional layers를 가지며, 그 중에 일부는 max pooling layer를 가지고 있습니다.
그리고 마지막에는 3개의 fully-connected layer를 가지게 됩니다.
최종 layer 출력은 1000개의 softmax로 구성됩니다. train 속도를 위하여 non-saturation neurons과 효과적인 GPU 구현을 이용 하였습니다.
그리고 Overfitting을 줄이기 위하여 dropout 기법을 이용하여 regularization을 하였습니다.
ILSVRC-2012 Contest에서 model을 변형하여 2등과 큰 차이로 우승 하였습니다.

Datasets

train에 사용된 데이터 셋은 imageNet 입니다.
imageNet 딥러닝의 대모이신 Fei Fei li 교수님이 만드신 걸로, 1500만개의 high resolution 이미지를 가지고 있으며 약 22000개의 category를 가지는 대규모 데이터 셋 입니다.
ILSVRC는 Imagenet 의 일부를 이용하는데, 카테고리가 약 1000개에 약 1000개의 이미지가 있는 것을 이용합니다.
imageNet는 총 120만개의 train, 50000개의 valid, 150000개의 test image가 있습니다
imageNet은 이미지 크기가 다양 하므로 이미지 크기를 256*256으로 고정 하였습니다.
왜냐하면 나중에 Fully-connected layer로 입력시 크기가 고정 되어야 하기 때문입니다.
resize는 width height중에 짧은 곳을 256으로 변환, 그리고 center부분을 256 으로 cropped 하였습니다.
그리고 각 image의 pixel에서 traning set의 mean을 빼주었습니다.
그 외에는 데이터 pre-process를 하지 않았습니다.
Architecture
Network architecture의 요약은 논문의 Figure 2에 있습니다.

차근차근 하나하나 자기들이 설정한 기법에 대해서 설명합니다.
ReLU Nonlinearity

보통 평범한 방법으로 각 neuron 의 output은 tanh, sigmoid방식이 있습니다.
하지만 뭐. cs231n을 들은 사람은 알겠지만, 이 두개 방식은 sigmoid는 mean이 0이 아닌것, tanh는 이를 해결 하였지만
두개다 가지고 있는 고질적인 문제는 Saturated Neurons kill gradient 같은 문제가 있습니다.
그래서 Rectified Linear unit을 사용 합니다.
이는 Deep convolutional neural netwrok에서 tanh units보다 빠르게 작동합니다.
상식적으로 생각을 해봐도 max(0,x)보다 tanh가 더 계산량이 많다고 생각을 할 수 있을거같긴 하다.

CIFAR-10 Dataset에서 검증한 결과로 CIFAR-10은 10개의 카테고리 50000장의 Train, 10000장의 Test image가 있는 것 입니다. 그래프에서 보면 점선은 tanh이고, 실선은 ReLU입니다.
Epoch가 진행 될 수록 시간차이가 심해지는 것을 알 수 있습니다.
25% training error 까지 약 눈대중으로 보기에는 6~7epoch와 37epoch정도 같으니 약 6배정도 차이가 나는 것을 알 수 있습니다.
Training on Multiple GPUs


2012년 당시 GPU는 GTX580이였다.
Memory 용량이 3GB 파멸적인것을 알 수 있습니다.
Network를 train 시키기에는 부족한 양이라 여기서는 두개의 GPU를 이용하여 Training 하였습니다.
위에 그림을 보면 중간에 두개로 나눠지는 이유가 그러한 이유입니다.
Host를 거치지 않고 두개가 서로의 메모리에 접근이 가능하고, 두개의 GPU는 특정 Layer에서만 교환합니다.
Local Response Normalization
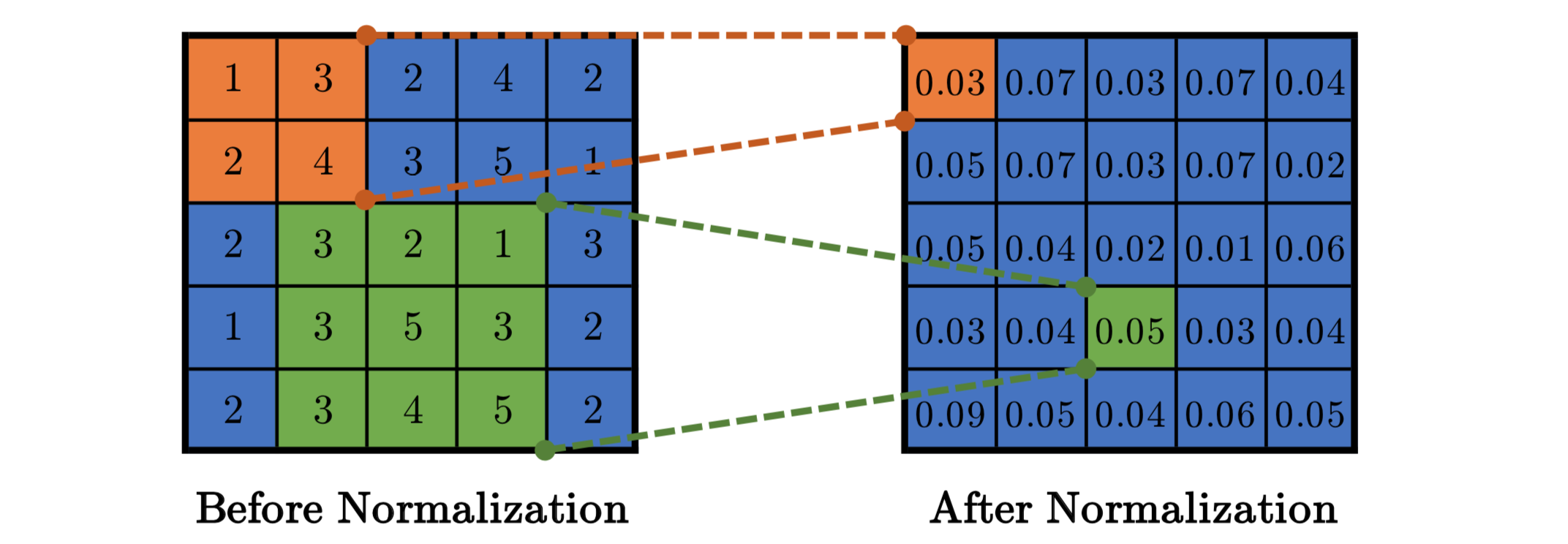
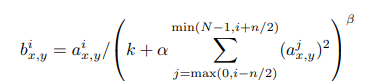
Relu가 gradient Saturation을 막는데 많이 도움이 됩니다.
하지만 이 방식의 normalization도 크게 도움이 되는데, Relu에나 나온 결과들을 같은 Spatial 위치의 인접한 Kernel map n개를 모아서 정규화 합니다. 요새는 안쓰는 방법이므로 심도 있게 알고 싶다면 검색하는 것을 추천드립니다.
현재는 Batch normalization을 사용합니다.
Overlapping Pooling
정통적인 방식은 겹치게 안했습니다.
Alexnet은 pooling size = 3, stride =2 즉 CNN에서 서로 Overlapping된는 max pooling을 수행 하였고, overfitting을
방지하는데 도움이 된다고 하였습니다. 실제로 top-1 top-5에서 error rate가 0.4, 0.3감소 한다고 하며, 다음과 같이 train중에 overlapping pooling이 존재하면 overfit이 어렵다고 합니다.
Overall Architecture
순서대로 정리 하겠습니다.
cs231n에서는 227*227*3 input이 맞네요. 왜냐하면 정상적으로 하였을때 227 이여야 한다니. 논문의 오류
간단하게 계산 하는 법은 (input - Filter size + 2*padding) / Stride + 1 입니다
[INPUT]
227*227*3 Size image
[CONV1]
96 11*11 Filter, Stride 4, Pad 0
INPUT : 227*227*3
OUTPUT : 55*55*96
[MAX POOL1]
3*3 Filter, Stride 2
INPUT : 55*55*96
OUTPUT : 27*27*96
[NORM1]
LRN 을 이용
INPUT : 27*27*96
OUTPUT : 27*27*96
[CONV2]
256 5*5 Filter, Stride 1, Pad 2
INPUT : 27*27*96
OUTPUT : 27*27*256
[MAX POOL2]
3*3 Filter, Stride 2
INPUT : 27*27*256
OUTPUT : 13*13*256
[NORM2]
LRN 을 이용
INPUT : 13*13*256
OUTPUT : 13*13*256
[CONV3]
384 3*3 Filter, Stride 1, Pad 1
INPUT : 13*13*384
OUTPUT : 13*13*384
[CONV4]
384 3*3 Filter, Stride 1, Pad 1
INPUT : 13*13*384
OUTPUT : 13*13*384
[CONV5]
256 3*3 Filter, Stride 1, Pad 1
INPUT : 13*13*256
OUTPUT : 13*13*256
[MAX POOL3]
3*3 Filter, Stride 2
INPUT : 13*13*256
OUTPUT : 6*6*256
[FC1]
INPUT : 6*6*256
OUTPUT : 4096
[FC2]
INPUT : 4096
OUTPUT : 4096
[FC3]
softmax
INPUT : 4096
OUTPUT : 1000
Reducing Overfitting
AlexNet은 600만개의 Parameter가 있으므로 Overfitting을 피하기 위해 몇가지 기법을 사용 하였습니다.
Data Augmentation
제일 쉬운 방법으로 overfitting을 피하는 방법으로 데이터의 양을 늘리는 것 입니다.
작은 연산으로 image Augmentation이 가능하기 때문에 GPU가 학습하는 동안 CPU가 Python code로 mini batch의 Augmentation을 진행 합니다.

가장 쉬운 방식은 반전 시키기 방식 입니다.
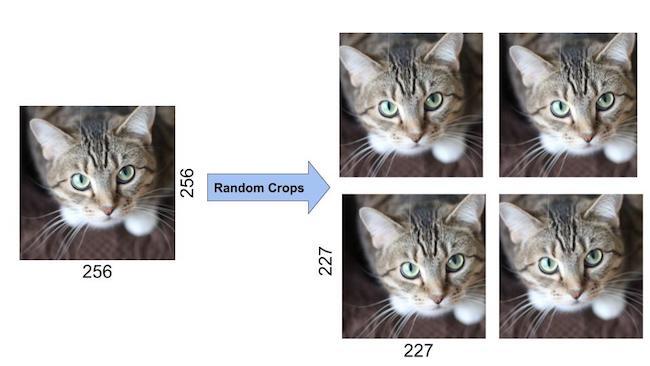
이미지 원본데이터에서 무작위로 이동하여 이미지를 추가하는데, 256*256 이미지 경계 내부에서 227*227 크기로 무작위로 자른 뒤에 추출이미지를 딥러닝 학습으로 이용 하였습니다. 이 방법으로 2048배 늘렸습니다.
자세히 보면 조금씩 다른 것을 알 수 있습니다.
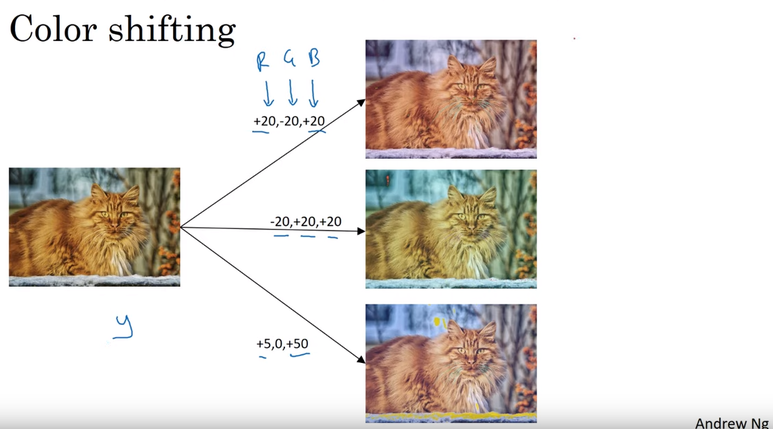
PCA color Augmentaton이란 dataset에서 RGB채널을 바꾸는 것 입니다.
PCA 주성분 분석을 통해 이미지 특성은 유지하지만 RGB값은바꾸는 것 입니다.
사실 PCA부분은 잘 모르겠네요 조만간 공부해서 POST 하겠습니다.
Drop out
FC Layer의 부분에서 drop 아웃을 진행합니다. drop out의 확률은 0.5로 설정 하였으며, forwardpass와 backwardpass시 영향을 끼치지 않습니다. 매 입력마다 적용하여 가중치는 공유하지만 서로다른 구조를 가지게 됩니다.
이러한 방식으로 Overfitting을 방지합니다.
Details of learning

AlexNet에 사용된 것 입니다.
momentum=0.9, batch size=128, weight decay=0.005, SGD Momentum 를 사용 하였습니다
Weight초기화는 mean 0, std 0.01 가우시안 분포를 이용 하였습니다.
bias는 conv2,4,5와 FC에서는 1, 나머지는 0으로 하였습니다.
learning rate는 1e-2로 하였으며 validation error가 높아지지 않으면 10으로 나눠가며 하였으며, 총 3번 감소 하였습니다.
틀린부분이 있다면 댓글로 알려주시면 감사 하겠습니다.
'AI 공부 한 것' 카테고리의 다른 글
| [논문 리뷰] VGG Net(2014) 논문리뷰 (Very Deep Convolutional Networks for Large-Scale Image Recognition) (0) | 2022.01.18 |
|---|---|
| [논문 구현] AlexNet(2012) 논문구현 (ImageNet Classification with Deep ConvolutionalNeural Networks) (0) | 2022.01.12 |
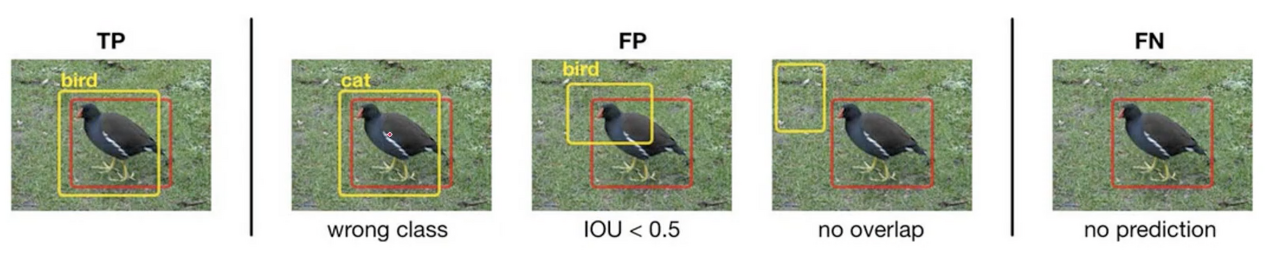
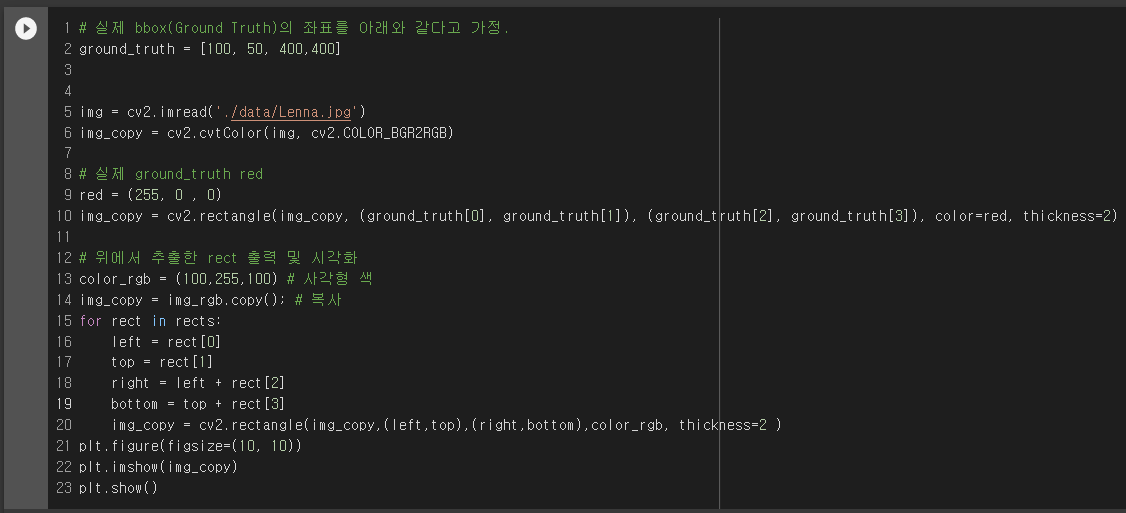
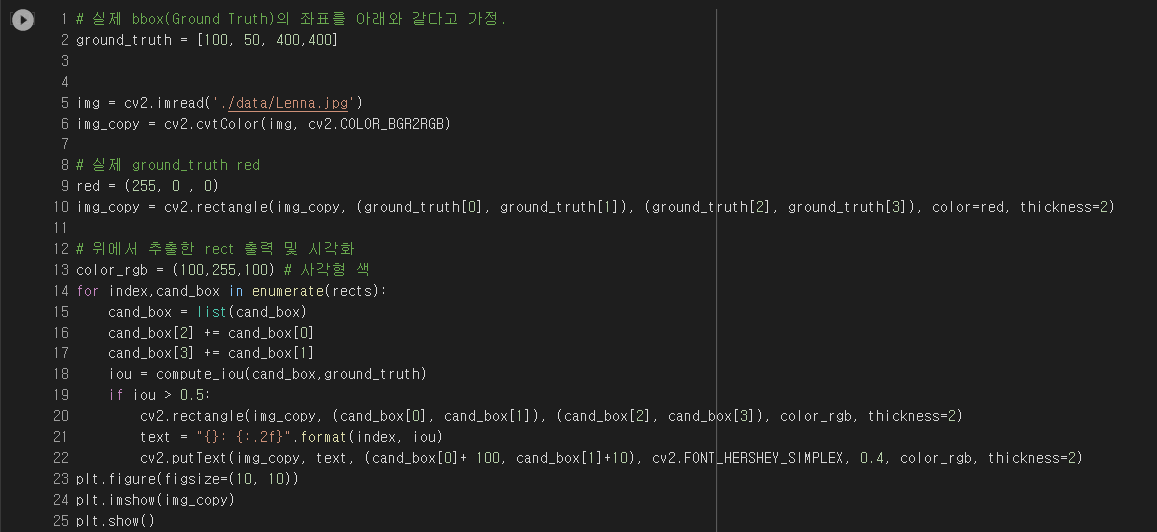
| [컴퓨터 비전] object detection 성능 평가 방법 (mAP, Precision, Recall) (3) | 2021.12.29 |
| [컴퓨터 비전] NMS (Non Max Suppression) (0) | 2021.12.28 |
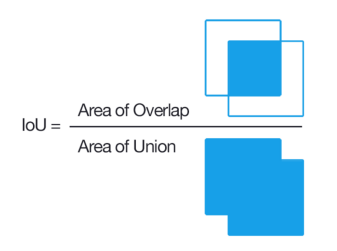
| [컴퓨터 비전] IoU(intersection over union) (0) | 2021.12.28 |