https://arxiv.org/abs/2201.04288
Multiview Transformers for Video Recognition
Video understanding requires reasoning at multiple spatiotemporal resolutions -- from short fine-grained motions to events taking place over longer durations. Although transformer architectures have recently advanced the state-of-the-art, they have not exp
arxiv.org
Abstract
- Video Understanding은 Short Fine-Grained Motion(짧고 세밀한 동작)에서 장기간에 걸쳐 발생하는 Event까지 Multiple Spatiotemporal Resolution에서 추론이 필요
- Transformer Architecture는 최근 SOTA가 되었지만, 다른 Spatiotemporal Resolution을 명시적(Explicitly)으로 모델링하지 않음
- 저자들은 이런것을 보고 Multiview Transformer for Video Recognition(MTV)를 제시함
- 저자들의 Model은 Input Video에서 다양한 View를 나타내는 별도의 Encoder로 구성되어 있고, Lateral Connection으로 다른 View들을 통합
- 저자들의 Model에 대한 Ablation Study를 제시하고, MTV가 다앙한 Model 크기에 걸쳐 Accuracy, Cost측면에서 일관되게 Single View 보다 더 좋은 성능을 보임
- 6개에서 SOTA, Pretrain을 통해 성능 향상
Introduction
- Vision 구조는 CNN 기반, 최근에는 Transformer가 이를 대체하여 많은 발전을 이룸
- Handcrafted Feature, CNN, Transformer까지 Classical Method 전반에 걸쳐 일정하게 유지 된 것은 여러 Resolution을 분석하는 것 - Image Domain에서 MultiScale Processing을 Natural Image의 Statistics이 isotropic(All Orientations Equal), Shift Invariant 이기 때문에 일반적으로 Pyramid로 수행(Natural Image내의 통계적 특성이 Orientation, Location에 관계없이 비교적 일정하다는 것, 그러므로 Pyramid를 이용하여 여러 척도에 걸쳐 관련 정보를 효율적으로 캡처 가능)
- Video의 Multiscale Temporal Information을 Modeling하기 위해 SlowFast와 같이 High Frame Rate로 작동하는 'Fast' Stream, Low Frame Rate로 작동하는 'Slow' Stream을 사용하여 Video를 처리하거나 Long Rate Interaction을 Modeling하기 위해 Graph Neural Network를 이용하기도 함

- Pyramid Structure를 만들때 Spatio-Temporal Information은 Pooling, Subsampling 으로 인해 Information이 손실됨
- 예를 들어 SlowFast Network은 Stream을 구성할 때 Frame을 Subsampling하여 Temporal Informaton이 Loss됨
- 이 논문에서 저자들은 Simple Transformer Based Model로 Multi Resolution Temporal Context를 Capture가능하도록 함(Pyramid 구조를 이용하지 않고, SubSampling을 하지 않고)
- 저자들은 Multiple Input Representations 또는 Input Video "View"를 활용
- Figure1에 나타난 바와 같이 Input Video에서 여러 시간동안에 Token을 추출
- 직관적으로 Long Time Intervals에서 추출된 Token은 장면의 요지(활동이 일어나는 배경)를 Capture하는 반면 Short Segment에서 추출된 Token은 사람이 수행하는 Gesture와 같은 fine-grained details을 Capture
- 저자들은 이런 Token을 처리하기 위해 Multiple View Transformer를 제안(Figure1)
- 각각의 View에 특화된 별도의 Transformer Encoder로 구성
- 서로 다른 'View'의 Information을 통합하기 위해 Lateral Connection이 있음
- 각 'View'를 처리하기 위해 다양한 Size의 Transformer Encoder를 사용할 수 있음
- Smaller Encoder(Small Hidden Size & fewer Layer) Represent Borader View of th Video(FIg.1 Left)(in terms of accuracy/computation trade-offs)
- 더 큰 Capacity를 가지는 Encoder를 사용하여 Detail Capture도 좋음(Fig. 1. Right)
- 이런 Design은 Spatio-Temporal Resolution이 감소함에 따라 Model Complexity가 증가하는 Pyramid-Base 접근 방식과 대조를 보이고, 이를 실험으로 검증
- 저자들의 제안은 Input Video의 "View"를 처리하는 간단하고, 이전 연구와 대조적으로 다양한 'View'로 쉽게 Generalizes를 진행
- 실험에서 보면 'View'가 늘어날 수록 Accuracy가 증가
- 제안한 구조는 Input View의 수에 따라 Network에 의해 처리되는 Token수가 증가하지만, "Small"에서 "Huge"에 이르는 Model 크기의 스펙트럼에서 Accuracy/Computation Trade-Off
- 저자들은 이것이 더 많은 View를 Parallel로 처리하는 것이 Transformer Network의 Depth를 증가시키는 것 보다 더 높은 Accuracy 향상을 달성 가능(실험)
- Design Choice에 대해 Ablation Study를 진행하여 6개 Task에 대해 SOTA에 달성
Related Work
- Evolution of video understanding models
- Hand-Crafted Feature에 의존하여 Motion 및 Appearance Infomation을 Encoding
- ImageNet 등장으로 Large-Scale Dataset의 등장으로 CNN은 기존보다 우수
- AlexNet이 ImageNET에서 우승하고 여러 세대 걸쳐서 진화 및 NAS에서 개선
- Kinetics 등장 후에 3D CNN이 인기를 얻고, Speed와 Accuracy를 높이는 방향으로 많은 변형이 개발
- 하지만 CNN은 Local만 가능하고, 결과적으로 Transformer Block은 Spatiotemporal Feautre 사이의 Long-Range Interaction Modeling을 Capture하기 위해 뒷단에 추가
- Pure Transformer Model은 ViT가 출발을 했고, Video 분야에서 ViViT, TimeSformer는 성공적으로 자리잡음 - Multiscale processing in computer vision
- 'Pyramid' 구조는 Image에서 가장 인기있는 Multi Scale Representations 중에 하나이며 다양한 Vision Task 핵심
- 여러 Domain에서 널리 사용됨
- 해당 아이디어는 Network의 Spatial 차원이 감소하고, Network Depth는 점차 증가하여 풍부한 Feautre를 Encoding하는 현대 CNN에도 성공적으로 이용됨
- 해당 기술은 Downstream Task에 대한 HighResolution Output Feature를 생성하는데 사용
- CNN에서 Convolution 작업이 Input의 Sug-Region에서만 작동하고, Image 또는 Video 전체 'View'를 Capture할려면 Hierarchical Structure이 필요하기 때문에 Multi-Scale 처리가 필요
- 이론적으로 그러한 Hierarchical 구조는 Token이 다른모든 Position에 Attend하는 Transformer에 필요하지 않음
- 실제로 Training Data의 양이 제한되어 있기 때문에 Transformer와 유사한 Multi Scale Process를 적용하는 것이 효과적(Swin Transformer Etc) - 저자들의 Model
- Pyramid Structure를 따르지 않고, Video의 Different VIew를 직접 가져와서 Cross-View Encoer에 공급
- 실험에거 검증하는데, 이런 Multiple View구조는 Accuracy, Flops trade-offs측면에서 Single-View Architecture보다 좋음
- 이는 더 많은 View를 Parallel하게 처리하는 것이 Transformer의 Network Depth를 증가시키는 것보다 더 큰 Accuracy 향상을 제공
- 이전의 Pyramid Structure Transformer에서 보여주지 않은 10억개 이상 Parameter로 Model Capacity를 확장함에 따라 개선됨을 보여줌(가장 거대한 모델)
- 개념적으로 동일한 Video Clip의 두개의 View를 처리하는 Two Stream CNN SlowFast와 유사
- 서로 다른 Frame 속도로 Input Video를 Sampling하는 대신, 각 View에 대해 다양한 Size와 'Tubelets'을 Linear Projection하여 다른 View를 얻음
- 또한, 우리는 제안된 방식이 가장 좋은 결과를 얻음
Multiview Transformers for Video
- Preliminaries: ViT and ViViT
- Input Video : V ∈ R (T×H×W×C)
- Transformer 구조는 Input을 Discrete Token으로 Convert하여 Input을 처리, 이후에 여러 Transformer Layer를 순차적으로 처리 - - ViT에서는 Image Token 추출을 Non-Overlapping 되게 분할하고, Linear Projection을 진행
- ViViT에서는 N개의 Non-Overlapping Patch를 추출하는데, Spatio-Temporal Tube(Tubelets)을 이용
- Patch 가 다음과 같다면 : x1, x2, . . . xN ∈ R (t×h×w×c), N = [T/t] x [H/h] x [W/w] - 각 Tube xi는 Linear Operator E로인해 zi = Ex, zi ∈ R(d)가 됨
- 모든 Token은 E를 거친 뒤에 Concat됨, 그 이후에 CLS Token을 앞쪽에 부착
- Transformer는 permutation invariant(Vector 요소와 순서에 상관없이 같은 Output)한데, positional embedding p ∈ R (N+1)×d도 더해준다.


- Linear Projection E는 Time, Height, Width 차원에서 각각 Kernel Size가 t x h x w이고 Stride가 (t,h,w)인 3D CNN으로 볼수가 있음(Patch Embedding을 3D CNN으로 수행)
- 이후에 z를 Encoder에 집어넣어 MSA, MLP를 진행
- 최종적으로 CLS Token을 이용해서 Classification을 수행
- Multiview tokenization
- 해당 Model에서는 Input Video에서 Multiple Set Of Token을 추출함
- 아래와 같은 Notation에서 V는 'View'의 개수, l은 Transformer Layer 몇개를 통과한것이냐, i는 View의 Index
- 저자들은 View를 Fixed Size의 Tube Set으로 정의
- Larger View는 Larger Tubelet을 가지고(Fewer Token), Smaller View는 Smaller Tubelet(More Token)
- 0번째 Layer는 Subsequent Transformer의 Input으로 들어가는 Token
- 일반적으로 3D Convolution을 이용해서 Tokenize하는데, 이런 방식이 더 좋음
- 각 View에 대해서 서로 다른 Convolution Kernel과 서로 다른 Hidden Sizes인 d(i)를 이용한다
- Convolution Kernel이 작을수록 더 작으 Spatio Tubelet에 해당하므로, i번쨰 View에 대해 처리할 Token이 많아짐
- 직관적으로 작은 Tube는 fine-grained Motuon을 Capture하고, 큰 Tube는 장면의 천천히 변화하는 Sematic를 Capture할 수 있음
- 각 View는 서로 다른 Level의 Information을 Capture하므로, 각 Stream에 대해 다양한 Capacities의 Transformer Encoder를 사용하고, Stream간의 Lateral Connection을 이용하여 정보를 Fuse



- Multiview Transformer
- Multiple View의 Token을 추출하면 아래과 같은 Set을 얻게됨
- Self Attention을 Quadratic Complexity를 가짐
- 모든 View Token을 다같이 처리하면 Video에서는 불가능
- 따라서 먼저 View간의 Token을 처리하기 위해 별도의 Transformer Encoder(Li)로 구성된 Multi View Encoder를 이용하고, 이런 Encoder간의 Lateral Connection을 이용하여 각 View간의 정보를 공유(Figure2)
- 마지막으로, 각 View에서 Token Representation을 추출하고 이를 Final Global Encoder와 함께 처리하여 Final Classification Token을 생성하고, 이를 이용해서 Output를 생성

- Multiview Encoder
- Multiview Encoder는 각 View에 대해서 별도의 Encoder로 구성, 이 Encoder는 Lateral Connection으로 Cross-View Information을 융합
- Encoder 내의 각 Transformer Layer에는 다른 Layer내에서의 다른 Stream의 Information을 선택적으로 Fuse하는것을 제외하고는 동일
- 저자들의 Model은 Transformer Layer의 유형에 영향을 받지 않음
- 각 Transformer Layer내에서는 동일한 Temporal Index내에서 추출된 Token들 사이에서만 Self-Attention을 계산(Factorised Encoder를 이용), 계산 비용을 줄일 수 있음
- 또한 Multiview Encoder 내에서 다른 View의 Information을 융합하고, 모든 Stream Token은 집계하는 Subsequent Global Encoder로 인해 모든 Spatiotemporal Token에 대한 Self-Attention이 필요하지 않음 - Cross-Veiw Fusion
- 총 3개의 Cross-View Fusion Method(CVA, Bottleneck Token, MLP Fusion)를 탐구, 각 View에 대해 Hidden Dimensons은 다를수도 있음 - Cross-View Attention(CVA)
- 서로 다른 View간의 Information을 결합하는 가장 Straight-Forward한 방식은 모든 Sigma(i)(Ni) Token에 대해 공동으로 Self-Attention을 취하는 것 이다. 이때 Ni는 i번째 View에 있는 Token의 수, 한마디로 모든 Token에 대해 Attention
- 이 방식은 Quadratic Complexity를 가지는 Self-Attention에서는 불가능, 더욱이 Video Model에게는 이용하면X
- 인접한 두개의 View인 i와 i + 1의 모든 Pair사이의 Information 순차적으로 융합하며, View는 Token 수가 증가하는 순서로 정렬됨 [N(i) ≤ N(i+1)] ( i는 큰 View, i+1은 작은 View)
- 더 큰 View의 Token을 Update하기 위해 Query는 z(i), key 와 Value는 z(i+1)로 Attention을 계산
- Token의 Hidden Dimension이 다를수도 있기 때문에 Key와 Value를 Linear Layer를 이용해서 Projection
- 나머지는 Residual Connection, Attention 메카니즘은 동일

- Bottlenect Tokens
- 특정 Token, 즉 BottleNeck Token을 이용해서 Information을 교환하는 방식
- B(i+1)은 i+1 View BottleNeck의 개수, d(i+1)은 i+1 View Hidden Dim을 의미
- 아래의 그림은 B = 1인 경우, i+1번째 View의 BottleNeck Token Z_B^(i+1) 은 동일한 Z_ ^(i+1)과 Attention을 취하고, 이후에 다음 Attention을 취하기 전에 i번째 View로 BottleNeck Token을 전송(Linear Layer로 Dim을 맞춤)
- Token수가 많은 View부터 시작해, 적은 View로, 모든 View Pair간에 Fusion가능
- 직관적으로 보면 가장 적은 View가 모든 View의 세분화된 정보를 종합
- 새로운 Parameter는 Linear Projection과 BottleNeck Token

- MLP Fusion
- 각 Transformer의 Encoder Layer는 MSA와 MLP Block으로 구성됨
- 간단한 방법은 MLP Block앞에서 Fusion 하는 것
- Figure2c의 그림을 보면 View i + 1, z(i+1)의 Token과 Hidden Dimension d(i+1)을 따라 View i의 Token과 연결
- 그 뒤에 해당 Token은 Layer i의 MLP Block에 공급되어 d(i)로 투영됨
- 이 과정은 Network의 Adjacent View간에 반복되며, 다시 한 번 View당 Token수가 증가함에 따라 View가 정렬됨
- Fusion Location
- Fusion Operation에서 Previous View의 모든 Token을 고려하는 Global Receptive Field가 있기 때문에 서로 다른 View간의 정보를 전송하기 위해 Cross-View Encoder의 각 Layer에서 Cross-View Fusion을 할 필요가 없음
- 또한 각 개별 View Encoder의 서로 다른 Depth를 가질 수 있는데, 이는 View i의 Layer l과 View j의 Layer l'사이에서 Fusion이 발생 할 수 있음( l과 l' 다름)
- 따라서 Fusion 위치를 정하는 Ablation Study를 진행 - Global Encoder
- 마지막으로 Figure1과 같이 Final Global Encoder로 각 View의 Token을 집계하여 Cross-View Transformer 이후 모든 View의 Information을 효과적으로 Fusion
- 각 View에서 CLS Token을 추출하고, 모든 View의 Information을 취합하는 방법에 따라 다른 Transformer Encoder로 추가 하여 처리
- 그 뒤에 CLS Token C개의 Classification Output으로 Mapping됨
Experiments
- Model Variants
- 5개의 Tiny, Small, Base, Large ,Huge까지 5가지의 ViT Variants를 이용
- 예를 들어 B/2+S/4+Ti/8은 3개 View Model을 나타내고, Base, Small, Tiny Encoder는 각각 16x16x2, 16x16x4,
16x16x8의 3개의 Tubelet을 이용,
- ViT에 따라 Huge Model(14x14)을 제외한 Model은 Tubelet의 Spatial Size가 16x16을 이용, 그러므로 생략
- Base Model들은 Head가 12개가 아닌 8개로 설정
- 그 이유는 Multi Head Attention을 위해 Token의 Hidden Dimension을 Head로 나눠야 하기 때문에 - Training and Inference
- 별도의 Setting이 없는 한 ViViT의 Setting을 그대로 이용
- 모든 Model은 Temporal Stride가 2인 32 Frame으로 Training
- Linear Warming Up, Cosine Learning Rate Decay, Momentum 0.9, Synchronous SGD를 이용
- Input Frame의 Resolution은 Training과 Inference 224x224로 설정
- ViViT와 동일한 Data Augmentation 및 Regularization을 적용
- Inference 동안 Multiple Spatial and Temporal Crop을 이용한 뒤에 평균을 취함
- Crop의 수는 Result Table에 나옴 - Initialization
- 이전 Task에 따라 ImageNet Dataset에 Pretrain된 ViT Model을 이용하여 초기화
- 초기 Tubelet Embedding Operator E와 Position Embedding p는 Pretrain된 Model에서 서로 다른 Shape가지는데, ViViT와 동일한 Method로 (Central Embedding, ViT의 Position Embedding을 Temporal 축에 따라 Repeat)
- Final Global Encoder는 Random으로 Initialization을 진행

- Dataset
Kinetics
- Large-Scale, High-Quality Dataset으로 10s Video Clip(Human Action)
- 400,600,700 3가지 Version이 존재하고, Class의 수를 의미
Moments in Time
- 800000개의 Label이 붙은 3s Video 모음
- 사람, 동물, 사물, 자연 현상과 관련
Epic-Kitchens-100
- 주방에서 촬영된 총 100시간 분량의 90000개의 Video
- 각 Video마다 noun, verb 명사와 동사 Label이 지정되고, 두개의 Head를 가진 단일 Network를 이용하여 두가지 Category를 Predict
- 일반적으로 해당 Dataset은 ('noun', 'verb', 'Action')3개의 Accuracy가 이용되고, Action Label이 Primary Metric이 됨
- 'Action' Label은 가장 높은 Score를 받은 'noun', 'verb' Pair를 선택하여 구성
Something-Something v2
- 220000개가 넘은 Short Video Clip을 가지고 있고, Human이 다른 Object와 행동을함
- 비슷한 Object, Background는 여러 Class내의 Video에 나타남
- 따라서 다른 Dataset와 달리 해당 Dataset에서는 Motion에서 Class구별하는 Model의 능력이 중요 - Ablation Study
- Kinetics 400 Dataset에서 Ablation Study를 진행
- Largest Backbone은 Base를 이용하여 빠른 실험을 진행
- Spatio Temproal Crop을 이용하는데 4개의 Temporal Crops, 3개의 Spatail Crop, 총 12개를 이용
- 30 Epcohs, Lr 0.1

- Model View Assignment (a), (b)
- View는 Tubelet으로 표현된 Video Representation이고, Larger View는 Larger Tubelet, Small View는 Small Tubelet
- 예를 들면 B/8 + Ti2 는 Base Model은 16x16x8 Tubelet, Tiny Model은 16x16x2 Tubelet, Tubelet이 작아지면 Token수는 증가
- Table1을 보면 Smaller View를 Larger Model에 적용하는 것이 좋은 결과가 나옴
- B/2 + S/4 + Ti/8은 81.8%의 Accuacy을 받았지만, B/8+S/4+Ti/2는 78.5%의 Accuracy를 얻음
- FLOPs가 증가해서 그렇다고 주장할 수 있지만, 비슷한 FlOPs를 가지는 B/4+S/8+Ti/16에 비해 좋은 결과를 얻음
- Larger View를 Capture하는 경우에는 Scene의 요지를 파악하기 때문에 덜 복잡하고, Scene의 Detail은 더 작은 View로 캡슐화 되므로 더 큰 Model이 필요
- 또 다른 전략으로는 모든 View에 동일한 Model을 할당
- Table1의 b를 보면 세가지 모두 큰 차이가 존재하지않고, GFLOPs와 Parameter만 증가하는 문제가 생김 - What is the best cross-view fusion method?(c)
- Table1의 c를 보면 3개의 View Model에 대해 다양한 Fusion 방법을 비교
- Late Fusion, Ensemble, MLP, Bottleneck, CVA
- Ensemble은 단순히 각 View에서 생성된 확률을 합산, 각 View Model이 개별적으로 학습됨(가장 안좋은 성능)
- 해당 방식은 Small Model과 Tiny Model의 성능이 좋지 않기 때문임
- Late Fusion 방식은 Transformer가 생성산 Final Embedding을 Cross-View 없이 각 View에서 Global Encoder에 공급하기 전에 연결(80.6% 까지 개선)
- CVA, BottleNeck모두 좋은 성능이 나왔고, 제일 좋은 Accuracy를 보이는 CVA를 Main으로 진행
- MLP Fusion 방식이 안좋은 결과가 나온 이유는, MLP Block의 연결로 인해 Random 초기화 해야하는 Channel이 추가로 발생하여 Model의 최적화가 어려워짐 - Effect of the number of views(e)
- Table1의 e를 보면 View의 개수가 영향을 미치는 것을 연구
- View의 개수를 늘릴수록 Accuracy가 올라가는것을 확인 가능(2.5%, 2.8% 상승)
- FLOPs의 차이라고 볼 수도 있으므로, Base Layer를 증가시켜 Test
- 비슷한 FLOPs를 가지지만 Single View는 Accuracy가 미미하게 증가 또는 감소 - Which layers to apply cross-view fusion?(f)
- Fusion Method는 CVA를 이용
- B + S + Ti Model에서 각각 다른 위치에서 CVA를 적용
- CVA를 적용하는 Layer위치 ,Layer 수를 변경
- 하나의 Fusion Layer를 이용하면 적절한 위치 순서는 5, 0, 11 순서, 초기 Layer에서 Fusion을 하면 성능이 향상 x
- 중간 단계, Late단계의 Fusion을 이용하면 Accuracy 상승 효과가 존재, 하지만 초기 단계는 넣어도 개선안됨, 연속도 개선 x - Comparison to SlowFast(d)
- SlowFast와 비슷하게 구성했고, 적은 FLOPs 높은 Parameter로 우수 - Comparisons to state-of-the-art - Model
- MTV-B : B/2+S/4+Ti/8
- MTV-L : L/2+B/4+S/8+Ti/16
- MTV-H : H/2+B/4+S/8+Ti/16
- 모든 Kinetics Dataset 제외하고는 모두 Kinetic400을 Checkpoint로 이용
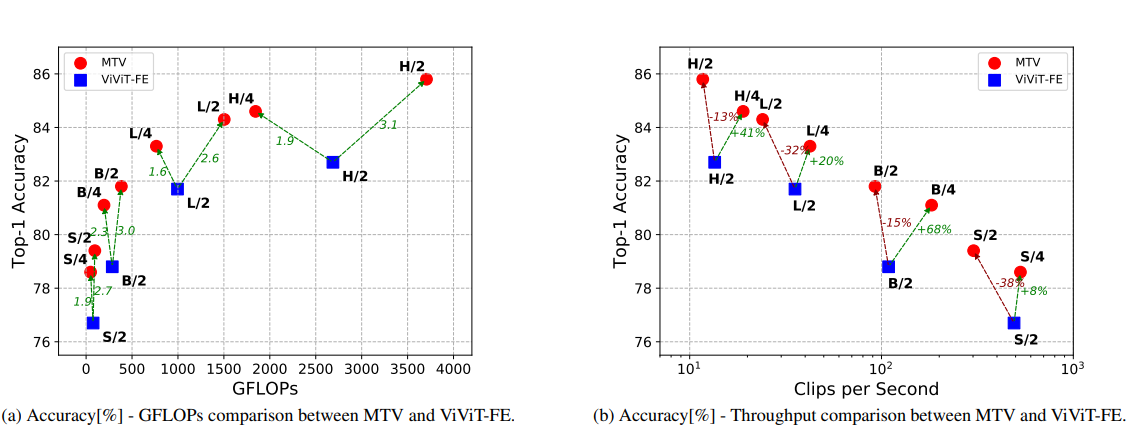
- Accuracy/Computation Tradeoff
- ViViT FE Model, MVT 모든 Model 간의 GFLOPs, Clip per Second를 비교
- Tubelets, Temporal Tube가 2인 경우가 가장 좋은 Performance
- 저자들은 Tubelet 크기를 조절하여 연산량을 조절가능(모든 View에 대해 비율로 Tubelet크기 조절가능)
- 연산량과 Accuracy 관점에서 보면 MTV가 ViViT-FE이 보다 좋음
- 이는 Network Depth를 늘리는 것 보다 여러 View를 병렬로 처리하는 것이 좋다는 것을 입증

- Which layers to apply cross-view fusion?(f)
- Kinetics 400, 600, 700 ImageNet Pretrain Model에서 우수한 성능을 보여줌(320p는 Spatial Resolution을 다르게 한 것)- 추가 Dataset(Weak Textual Supervision (WTS), JFT)으로 Pretrain을 더 진행한 결과 성능 향상을 더 얻을 수 있었음- SSv2, Epic Kitchens, Moments in Time에서 모두 우수한 Accuracy
- SSv2에서는 해상도가 높은 경우에만 MFormer보다 좋은 결과를 얻음