https://arxiv.org/abs/2212.04500
Masked Video Distillation: Rethinking Masked Feature Modeling for Self-supervised Video Representation Learning
Benefiting from masked visual modeling, self-supervised video representation learning has achieved remarkable progress. However, existing methods focus on learning representations from scratch through reconstructing low-level features like raw pixel RGB va
arxiv.org
Abstract
- Masked Visual Modeling의 이점을 활용하여 Self-Supervised Video Representation Learning은 놀라운 발전을 얻음
- 그러나 기존에 방법은 Raw Pixel RGB 값과 같이 low-level Feature를 Reconstruction하여 From Scratch로 Representation을 학습하는데 중점으로 둠
- 해당 논문에서는 Masked Video Distillation(MVD)를 제안, 간단하지만 효과적인 Two-Stage Masked Feature Modeling Frame Work인 MVD를 제안
- 먼저 Masking 된 Patch의 Low Level Feature을 Recovering하여 Image(or Video) Model을 Pre-Training 한 다음 Result Feature를 Masking된 Feature Modeling을 대상으로 이용
- Teacher Model의 선택을 위해, Video Teacher가 가르친 Student 들이 Temporal-Heavy Video Task에서 잘 수행하고, Image Teacher가 Spatially-Heavy Video Task에서 더 강력한 Spatial Representation을 Transfer
- 저자들의 Visualization Analysis를 진행 한 결과 다른 Teacher가 Student들을 위해 다른 Learned Pattern을 생성
- 이런 Observation이 동기를 부여하여 다른 Teacher의 Advantage를 활용하기 위해 MVD는 Spatial-Temporal Co-Teaching Method인 MVD를 제안
- 특히 Masking 된 Feature Modeling을 통해 Video Teacher, Image Teacher 모두에서 Student Model을 추출
- Extensive 한 실험에서 Sapatial-Temporal Co-Teaching으로 Pretrained 된 Video Transformer가 여러 Video Dataset에서 우수한 성능을 보임, (Single Teacher보다 우수)
- Vanilla ViT를 이용하여 SOTA에 달성(SSv2, AVA v2.2)

Introduction
- Self-Supervised Visual Representation Learning, Masked Image Modeling(MIM), MAE,BEiT, PeCO는 DownStream Task에서 인상적인 결과를 얻음
- Video Domain에서도 이런 Pre-Training 방식이 적용되었고, BEVT, ST-MAE, VideoMAE같은 Model들이 제안됨
- MAE, BEiT, 에 이어 기존 Masked Video Modeling 방법은 Raw Pixel Value또는 Low Leve의 VQVAE Token과 같은 Low Level의 Feature을 Reconstruction하여 VIdeo Transformer를 Pre-Training
- 하지만 Low-Level Feature를 Reconstruction 대상으로 하면 종종 많은 Noise가 발생
- 그리고 Video Data의 High Redundancy로 인해 Masked Video Modeling이 Shortcuts를 배우기 쉬우므로 Down Stream Task에 대한 Transfrer 성능이 제한됨
- 이런 문제를 해결하기 위해 Masking Video Modeling을 VideoMAE처럼 높은 Masking Ratio를 이용
- 해당 논문에서는 Pre-Train된 MIM, MVM Model의 High Level Feature를 Masked Prediction Target으로 사용하여 Masking Feature Prediction을 수행하여 Video Downstream Task에서 우수한 결과를 얻음
- 이것은 Two-Stage Masked Video Modeling으로 볼 수 있는데, MIM Pretrained Image Model, MVM Pretrained Video Model을 First Stage에서 얻고, 두개의 Model이 Second Stage에서는 Teacher처럼 동작하는데, High-Level Feature Target을 대상을 제공함
- 이런 방식을 Masked Video Distillation이라 정의
- 좀더 흥미로운 사실은, 저자들은 MVD에서 다른 Teacher로 Distilled 된 Student Model이 Video Downstream Task에서 다른 속성을 나타내는 것을 확인
- 구체적으로, Image Teacher 추출된 Student는 Spatial Cue에 집중, Video Teacher 에서 추출된 Model은 Temporal Cue를 추출
- 첫 단계에서 Masking 된 Video Modeling Pre-Training에서 Video Teacher는 High Level의 Feature에서 Temporal Context를 학습
- 따라서 Masking 된 Feature Modeling의 Target 대상으로 이러한 High Level Fature의 Representations을 사용할 때 Student Model은 더 강력한 Temporal Dynamic를 학습하도록 장려함
- 유사하게 Image Teacher또한 Student Model이 공간적으로 의미있는 Representation을 학습하는데 도움이 될 수 있는 더 많은 Spatial Information을 포함하는 Target으로 High Level Feature을 제공
- 저자들은 Image Teacher와 Video Teacher가 제공하는 Feature Target을 추가로 분석, Cross-Frame Feature Similarity을 계산
- Video Teacher가 제공하는 Feature는 더 많은 Temporal Dynamic을 포함하고 있음을 보여줌
- 위의 Observation에 부여하여 Video, Image Teacher의 장점을 활용하기 위해 MVD를 위한 간단하고 효과적인 Spatial-Temporal Co-Teaching Strategy를 제안
- 자세히 보면 Student Model은 두 개의 다른 Decoder로 Image Teacher와 Video Teacher 모두에서 오는 Feature를 Reconstruction하여 더 강력한 Spatail Representation, Temporal Dynamic을 학습하도록 설계
- Experiments는 Image Teacher와 Video Teacher 모두 Co-Training을 통해 MVD 몇가지 까다로운 Downstream Task에서 Single Teacher를 이용한 것보다 우수
- 이러한 단순함에도 MVD의 Co-Training은 매우 효과적이고, 여러 Standard Video Recogniton Benchmarks에서 우수한 성능
- SSv2, Kinetics-400에서 MVD가 없는 Base와 비교하여 같은 Size의 Teacher Model을 사용하여 400 Epochs보다 1.2, 2.8% Top-1 Score를 향상, SOTA에 달성
- 저자들의 Contribution은 아래와 같음
- MIM, MVM Pretrained 된 Model을 Teacher로 이용히여 지속적인 Masked Feature Prediction을 위한 High-Level Feature를 제공함으로써 더 나은 Video Representation을 학습할 수 있음을 발견, 이 두개의 Teacher Model을 다른 Video Downstream Task에서 다른 속성을 보임
- Image,Video Teacher의 시너지 효과를 이요아고, 효과적인 Co-Training과 Maksed Video Distillation 방법을 제안
- 여러 Video Recognition Benchmark에서 MVD는 SOTA에 달성
Related Work
- Vision Transformers for Video Understanding
- Video Understanding에 있어 Spatial-Temporal Modeling은 고려해야할 요소
- 초기에는 2D CNN을 3D CNN으로 확장
- 최근에는 Vision Transformer가 여러 Vision Task에서 진전을 이룸
- TimeSformer, ViViT에서는 여러가지 Spatial-Temporal Factorization을 연구
- 몇몇 Task(Video Swin, MViT)는 계산량을 줄이고, Locality라는 Inductive Bias를 Model에 주입
- Uniformer, Video MobileFormer는 효율성을 고려하여 3D-CNN과 Attention을 결합
- 해당 논문에서는 Vanila ViT를 이용하여 Pretraining 성능을 확인 - Self-Supervised Video Representation Learning
- 기존의 Self-Supervised Video Representation Learning은 Video이 Temporal 구조를 Base로 Pretext 작업을 설계
- 최근에는 Positive Pair는 가깝게, Negative Pair는 멀리하는 Contrastive Learning 방식을 차용
- 그러나 Contrastive Learning 방식의 Pre-Training은 Global Representation에 적용되어, Local 관계를 파악 못함 - Masked Visual Modeling
- Masked Language Modeling은 NLP분야의 지배적인 방법
- ViT에서도 성공적으로 도입됨(ImageMAE)
- VideoMAE에서는 매우 높은 Masking Ratio로 Video Patch를 잘 구성,MVD는 Masked Feature Modling에 중점을 두고 Image, Teacher Model을 이용하고, Student Model은 다른 속성을 가지고 보완 - Knowlefge Distillation
- Teacher Model의 Output을 Student Model의 Target으로 하여 Teacher Model의 지식을 Student Model에게 Transfer
- 일반적인 Knowledge Distillation은 주로 Supervised Learning(Image Classification)에 중점을 두고 있음
- 최근에는 Self-Supervised Pretrained Model에서느 Representation을 학습하기 위에 Self-Supervised Knowledge Distillation도 연구됨
- 해당 논문에서는 두개의 Teacher를 이용하여 각각 Domain에서의 유용한 정보를 Transfer
Method
- Masked Video Modeling은 Self-Supervised Learning을 위한 좋은 성능을 얻음
- 기존의 접근 방식은 Low-Level Information을 Reconstruction(Pixel, HOG, VQVQE Token)
- 해당 논문에서는 Low-Level Information을 Reconstruction하는 대신에 Feature Level에서 Masked Video Modeling을 수행
- 이는 쉽게 이용 가능한 MIM, MVM에서 나온 High Level Feature을 예측하도록 2단계 Framework인 MVD에 의해 달성
The Paradigm of Masked Feature Modeling
- Masekd Feature Modeling의 Core는 Maked Input Region의 Feature를 예측하도록 Model을 학습
- 이 논문에서 저자들은 Effectiveness와 Simplicity, MAE의 Decoupled Encoder-Decoder 아키텍처를 가짐
- Input X, Image는 (Ximg ∈ R(H×W×3), Xvid ∈ R(T×H×W×3)) 를 Non-Overlapping Patch로 분할
- 각 Patch는 Linear Projection Matrix를 이용하여 Visual Token으로 Mapping
- Transformer Encoder f에 Token을 전달하기 전에 Token의 Subset이 Mask되고, Input Token 시퀀스에서 삭제
- Masked Token의 Information 재구성 하기 위해 Encoder에서 Visible Token + Learnable Masked Token을 Transformer Decoder g에 전달
- Xvis는 Visible Input Token, Tm은 Mask Token
- 각 Masked Patch X(p)에 대한 Reconstruction Target은 Patch Feature h(X(p))로 표시
- 여기서 h는 Target의 Feature를 생성하는 Function
- 그 뒤에 Encoder과 Decoder를 Training시키기 위해 Masked Patch와 Reconstructed Patch의 Ground-Truth Feature Distance D를 측정하는 Loss Function을 정의
- p는 Token Index, M은 Masked Token Set, Pixel Regression MAE, VideoMAE에서는 L2 Loss를 사용
Masked Video Distillation
- 해당 논문에서 저자들의 MVD는 Low Level Pixel이 아닌 High Level Feature를 이용하여 Video의 Masked Feature Modeling을 수행
- 특히 쉽게 사용 가능한 off-the-shelf Self-Supervisd Pretrained Image또는 Video Model에서 생성된 Outpyt을 Reconstruction 대상으로 사용
- 이런 High-Level Feature는 Task의 Target은 MAE, VideoMAE와 같은 Masked Feature Modling으로 Pretrain된 Teacher Model로 인코딩됨
- Video Representation Learning의 경우 Reconstructuon Target은 Image & Video Model를 이용하여 Spatial, Temporal Feautre를 학습
- Image는 MAE 모델로 Pretrain, Video Model은 VideoMAE로 Pretrain 둘다 raw Pixel 재구성을 목표로 함
- Train되면, 저자들은 Image Encoder h_img 를 이용하여 Spatial Target을 생성하고, Pretrained Video Transformer Encoder h_vid로 Spatial-Temporal Target을 생성
- MVD Loss Function은 Image & Video -> L_mfm(h_img) , L_mfm(h_vid)를 이용
Spatial-Temporal Co-Teaching.
- MVD를 Single Teacher로 수행하면, 다른 Teacher로부터 Distill된 Student들이 다른 Video Representation을 배우고, Downstream Task에서 잘 수행되는 것을 확인
- 다양한 Downstream Video Task에서 MVD의 Accuracy를 상승시키고자, 저자들은 Spatial-Temporal Co-Teaching을 제안, Image, Video Teacher의 정보를 탐색하는 방법, 다양한 Video를 잘 처리하기 위해
- 예를 들면 인간의 행동이 빠르게 변하는 Video에서는 더 많은 Temporal Informaton이 필요
- 반면 상대적으로 정적인 Video에서는 Spatial 정보가 더 필요
- 이를 위해 MVD는 Image & Video Teacher가 동시에 생성한 High-Level Feature를 예측하도록 학습
- 두개의 분리된 Decoder를 이용하여 서로 다른 Target Feature를 Reconsturction하며 목표를 달성
- 아래의 3번식은 Spatial-Temporal Co-Teacher의 Loss함수
- λ1 and λ2는 Hyper-Parameter로 Image-Video Teacher의 Balance를 맞출 수 있음
- 아래는 Sudo Code
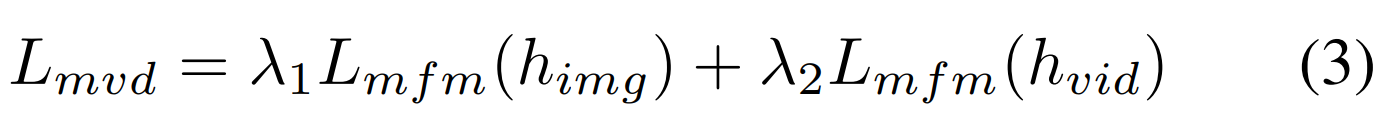

Architecutral Design
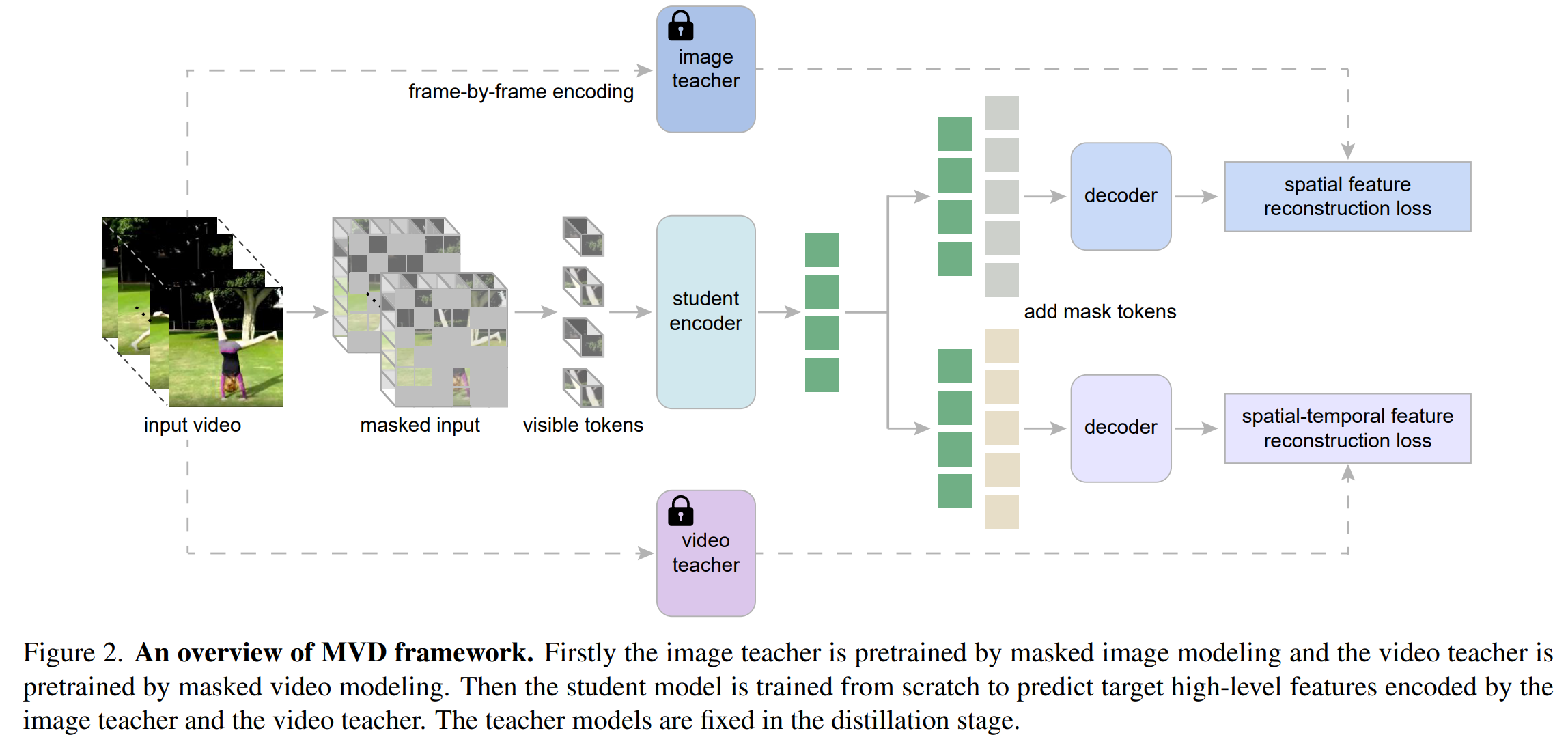
- Encoder
- MVD는 Vanilla Transformer Backbone을 이용
- 각 VIdeo Input은 X_vid ∈ R T×H×W×3, Tube Embedding을 차용하여 각 Patch Size는 2x16x16
- Patch Partitioning 이후에 Linear Embedding하여 T/2 x H/16 x W/16개의 Token을 얻음
- Masked Feature Modeling Task에서 High Masking Ratio를 이용하여 제거하고, Transformer Layer에 남아있는 Token들을 전달
- Fine Tuning DownStream Task에서는 모든 Token을 집어넣고, 각 Layer에서 Joint Spatial-Temporal Self-Attention을 진행 - Mask Strategy
- VideoMAE의 Tube Masking Strategy를 따름
- 우선 2D Random Mask가 생성된 다음 Temporal 차원에 따라 확장
- 그러므로 Spatial Mask은 각 Time Slice에서 같음, Information Leakage를 막을 수 있음
- Tube Masking은 High Masking Ratio로 진행하여 Video Transformer가 Hig-Level Sematics pretraining이 가능 - Decoder
- MVD는 Shallow Decoder를 가지는데, Vanila Transformer Layer와 Linear Projection Layer로 구성
- Decoder의 Transformer Layer는 Encoder의 Transformer Layer와 동일
- Spatial-Temporal Co-Training은 Masked Feature Modeling을 위한 Two Different Reconstruction Target을 이용
- 두개의 Separated Decoder가 동일한 아키텍처를 공유하지만, Weight가 다른 두개의 분리된 Decoder가 Encoder 상단에 배치됨
- Maksed Patch에 해당하는 Learnable Masked Token은 Decoder에 공급되기 전에 Encoder에서 Visible Token과 연결
- Spatial-Temporal 관계를 공동으로 Modeling 한 후에 Transformer Layer의 Output Token은 Linear Projection Layer에 의해 최종 Prediction에 Mapping - Reconstruction Target
- Spatial-Temporal Target Feature를 생성하기 위해, Student Model과 동일한 아키텍처를 공유하는 Video Teacher는 VideoMAE방식으로 Pretrain
- Spatial Target Feature를 얻기 위해 Vanila image ViT, ImageMAE
- Video Transformer에서 하나의 3D Patch(2 x 16 x 16)이 Image Transformer에 대한 두개의 2D Patch(16 x 16)에 해당
- Prediction Layer의 크기를 줄이는 Single Time Slice에 따라 Spatial Feature를 예측함
Experiments
- Dataset은 Kinetics-400, SSv2, UCF-101, HMDB51, AVA
- MVD는 ViT-S, ViT-B, ViT-L까지 4개의 Model을 사용
- Image Teacher는 ImageNet-1k에서 1600Epochs, Video Teacher는 K400에서 1600Epochs
- ImageMAE, VideoMAE의 방식을 따름
- Distillation Stage에서는 Student Model은 달리 언급이 없는 이상 From Scatrch로 K400에서 400Epoch로 Pretrain
- Video Clip은 16Frame이고, Smooth L1 Loss를 이용

Main Result
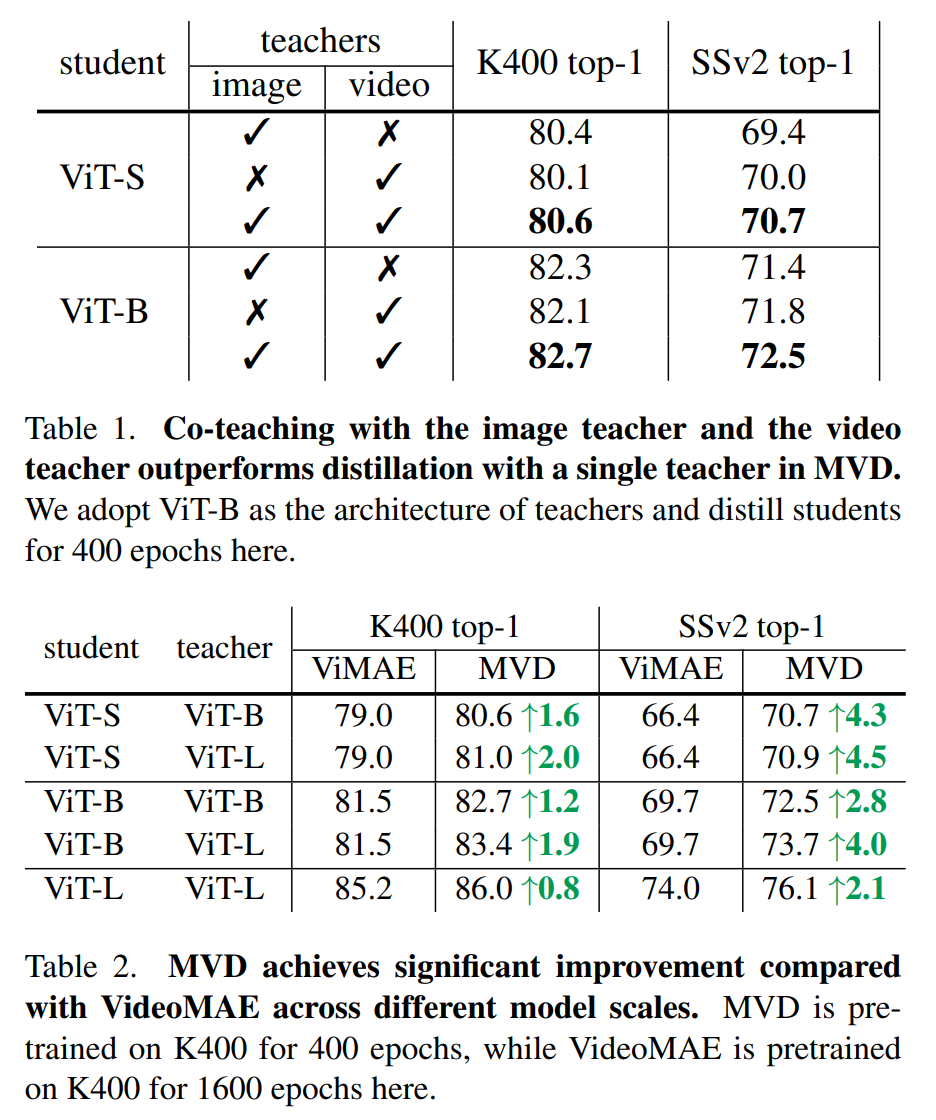
- Table1을 보면 Image Teacher를 이용하면 Spatial 정보가 중요한 K400에서는 Video Teacher보다 좋은 점수
- Temporally Heavy Dataset인 SSv2에서는 Video Teacher를 쓴 경우가 더 좋은 점수
- 결론적으로 저자들이 주장한대로 두개의 Teacher를 이용하면 더 좋은 점수를 얻음
- Table2의 VideoMAE와 비교해도 우수한 결과
- 하나의 Teacher에 비해 우수한 결과(Temporally Heavy , Spatail Heavy 모두에서)
Comparison With SOTA
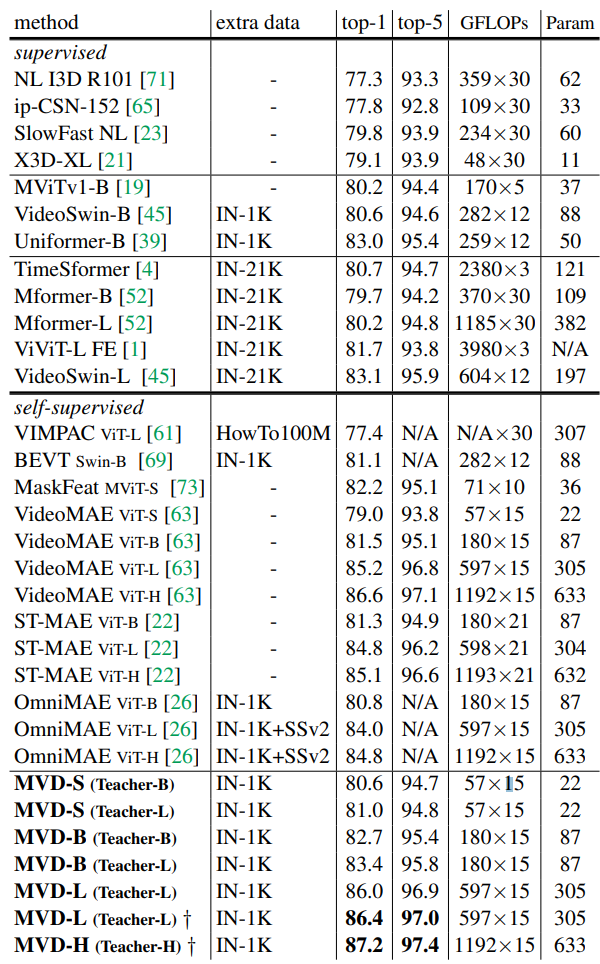
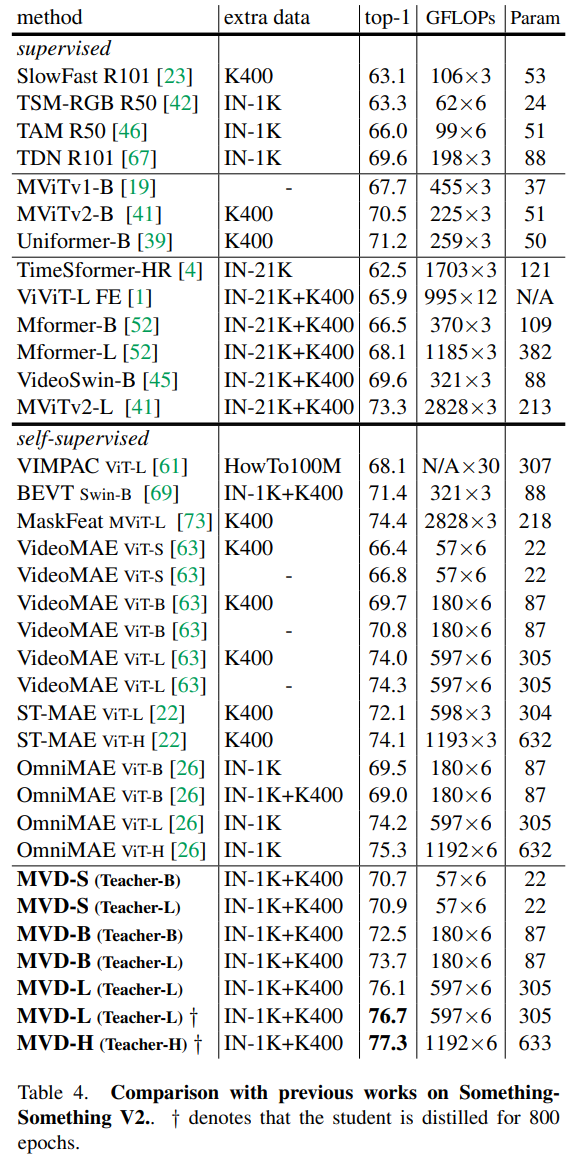
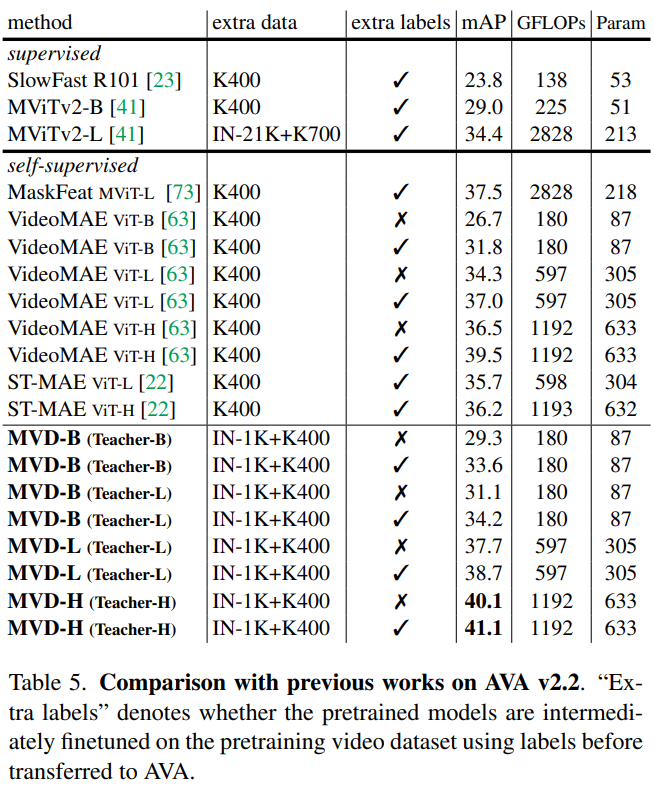
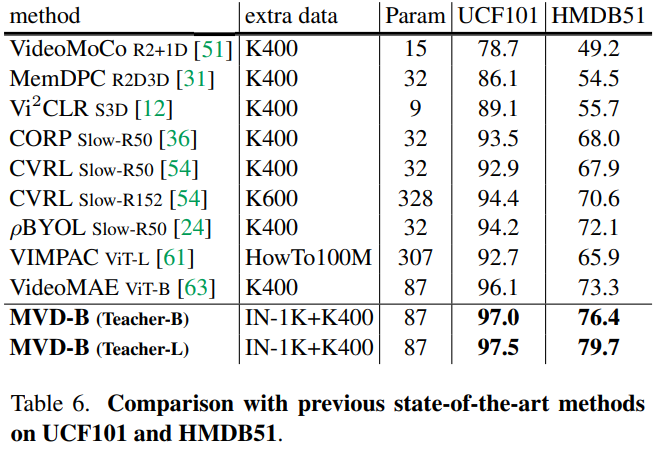
- K400에서 SOTA에 달성, SSV2에서 SOTA, AVA, UCF101, HMDB51에서 SOTA에 달성
Analysis and Discussion
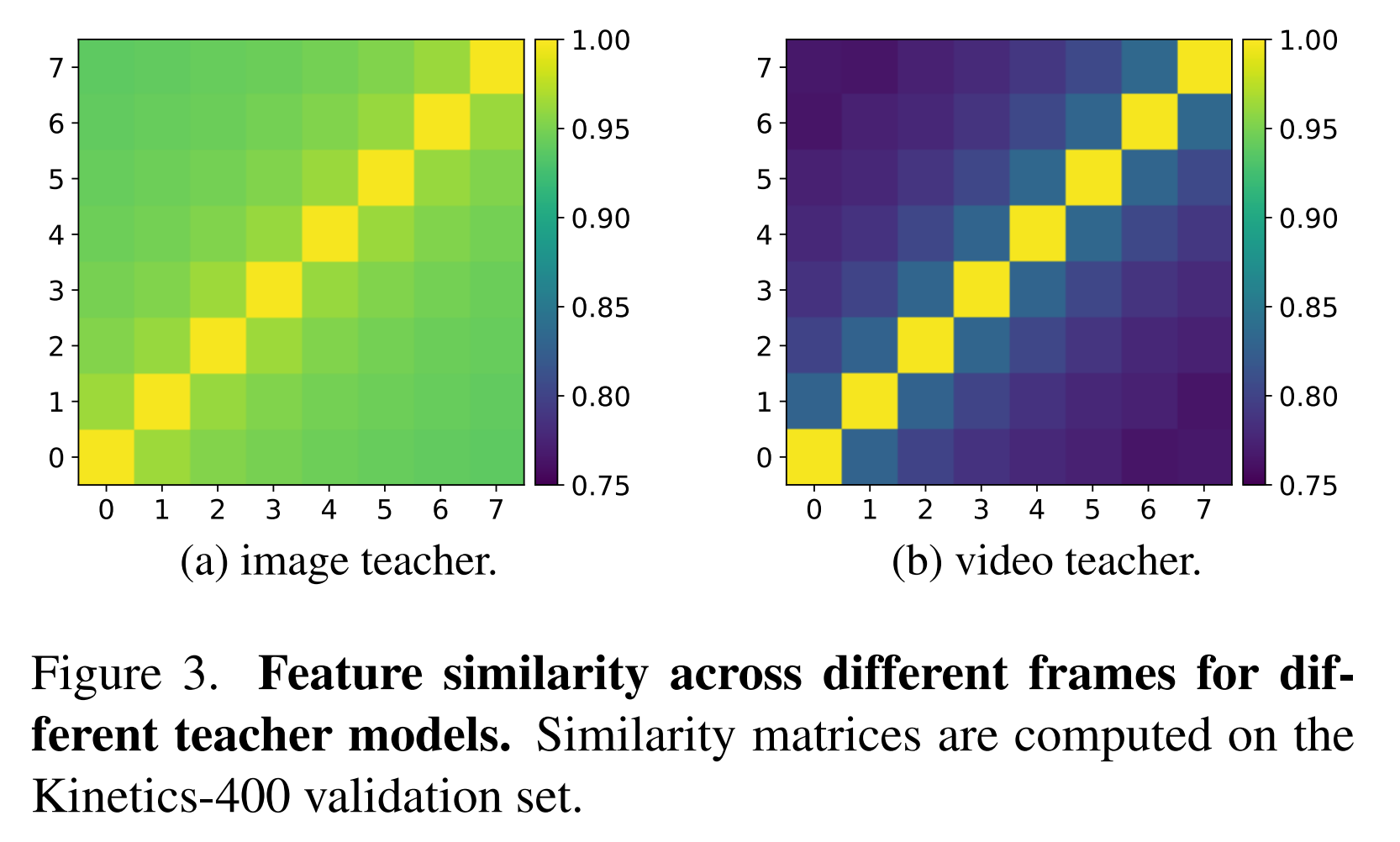
- Analysis of features encoded by different teachers
- 다른 Teacher가 생성한 Target Feature의 속성은 다른 Downstream Task에서 Student의 Performance에 영향을 줄 수 있음
- Teacher Model이 Input Video에서 Capture하는 Temporal Dynamics를 정량화하기 위해 Cosine Similarity를 구하고 이를 통해 각 Video Input에서 서로 다른 Frame에 걸쳐 Feature Map간에 유사성을 연구
- Image Teacher의 경우 각 Frame간의 Feature Map의 유사성이 높음(밝은색)
- 하지만 Video Teacher의 경우 서로 다른 Frame간의 Feature Map차이가 존재
- 이는 Video Teacher가 Temporal 정보를 더 잘 Capture 한다는 것
- 그러므로 Video Teacher가 추출한 것을 이용하면 Temporal Dynamic를 배우고, Temporally Heavy Dataset에서 유리하게 이용 가능
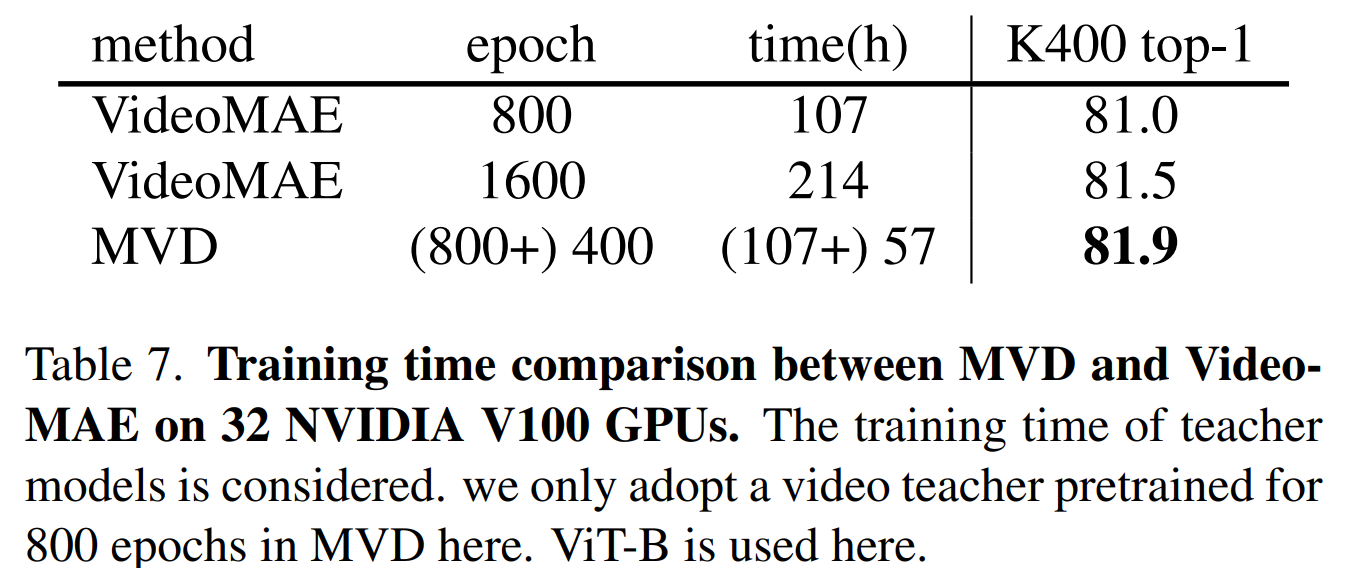
- Training Time Comparison
- MVD가 VideoMAE에 비해 정확도와 효율성이 높은지 확인
- 공정한 비교를 위해 Teacher Model의 교육 시간도 포함
- Table7이 결과로 MVD는 총 164시간, VideoMAE의 800시간보다 더 좋은 결과를 얻음

- Reconstruction signals in MVD
- MVD에서 우선 Teacher Model을 학습하는데, Masked Patch를 복구하는게 MAE의 방식(Pixel Level)
- Table에서 추가적인 연구를 진행, Distilation Stage에서 새로운 Decoder Brach를 이용하여 Pixel을 복구하는 것 추가
- Image Model로만 한 경우, 둘다 이용한 경우를 확인하면 Pixel Prediction을 추가하면 좋은 성능이 나오지 않는것을 확인
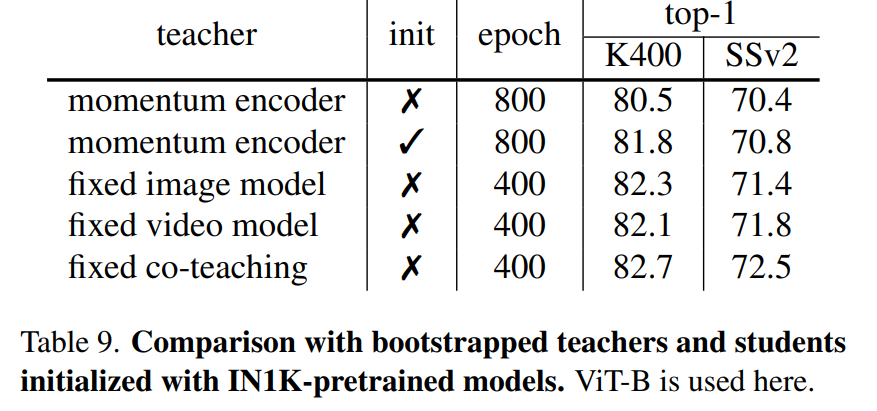
- Comparison with bootstrapped teachers
- 최근 몇몇 연구에서 Momentum Encoder Feature을 Maksed Image Modeling 대상으로 채택하는 방법을 이용
- MVD는 Fixed Teacher Model을 이용
- 저자들의 방식이 더 좋은 결과를 얻음
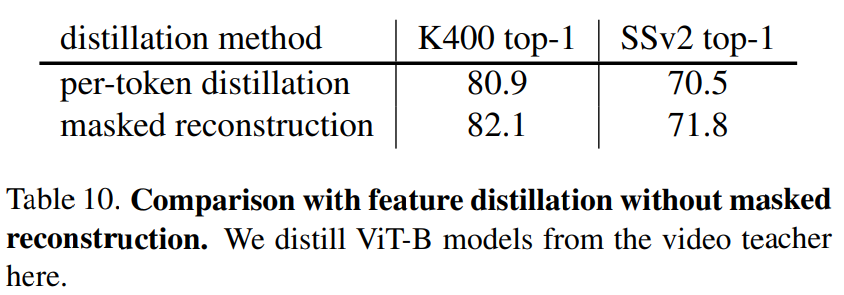
- Comparison with feature distillation
- 이전의 Self-Supervised Feature Distillation에서는 Distillation Loss를 Teacher, Student간에 전체 Feature Map에서 직접 계산됨
- 따라서 Per-Token Distillation을 Baseline으로 구축
- 특히 Student의 Output Feature은 MLP에 의해 투영된 다음에 Smooth L1 Loss로 각 Token에서 Teacher Model의 Feature를 모방하도록 강제됨
- MVD의 Masked Feature Modeling이 더 우수한 결과를 얻음
Conclusion
- Using MIM Pretrained Image Teacher + MVM Pretrained Video Teacher는 효과적으로 Finetuning이 가능해짐, Down Stream Task에서
- Image + Video Teacher에서 Distill 된 표현은 다른 속성을 가지고, Image Teacher는 공간, Video Teacher는 Video 작업에 이점을 가짐
- Image + Video Co-Training은 좋은 시너지 효과를 가짐