https://arxiv.org/abs/2201.00520
Vision Transformer with Deformable Attention
Transformers have recently shown superior performances on various vision tasks. The large, sometimes even global, receptive field endows Transformer models with higher representation power over their CNN counterparts. Nevertheless, simply enlarging recepti
arxiv.org
Abstract
- Transformer는 최근 다양한 Vision Task에서 최고의 성능을 보임
- 크고 때로는 Global 한 Receptive Field는 CNN Model보다 더 높은 Representation Power를 가진 Transformer모델을 제공
- 그럼에도 불고하고 단순히 Receptive Field를 확대하는 것은 몇 가지 문제가 존재
- ViT 같은 경우 Dense Attention을 이용하면, 과도한 Memory, Computational Cost가 존재, 또한 이미지를 Patch로 분할하고 이미지 전체(Patch)로 Self-Attention을 취하므로 관심 있는 영역을 벗어난 다른 비용에 영향을 받게 됨
- 반면 PVT 또는 Swin Transformer에서 이용된 Sparse Attention은 데이터에 적응적이지 않으며, 긴 거리에 대해 모델링하는 능력이 부족
- 해당 저자들은 이런 문제를 완화 하고자 새로운 Deformable Self-Attention Module을 제안, 해당 Module은 Query, Key Pair의 위치가 Data Dependent 하게 선택되도록 함
- 이러한 유연한 체계로 Self-Attention Module이 관련된 Region에 집중하고 더 많은 Information을 Capture 하도록 함
- 이를 바탕으로 저자들은 Deformable Attention Transformer를 제안, 해당 Deformable Attention Transformer는 Image Classification과 Dense Prediction Task에 General 하게 이용가능
- 다양한 실험으로 포괄적인 Bench Mark에서 개선된 결과를 얻음
Introduction
- Transformer는 원래 NLP Task들을 해결하기 위해 제안
- 하지만 최근에는 Vision 분야에서 높은 Potential을 증명함
- 이전의 진행되었던 ViT 같은 Model을 여러 개의 Transformer Block Stack을 만들고, Image 전체를 Non-Overlapping 되게 Patch Sequence(Visual Token)를 생성하여 Self-Attention을 진행, 이 방식은 CNN을 이용하지 않는 Image Classification Model이다
- CNN과 대응관계에 있는 Transformer Model을 넓은 Receptive Fields를 가지고, Long-Range Dependencies가 우수
- 이는 많은 양의 Training Data와 Model Parameter 체재에서 우수한 성능을 가지는 것으로 확인
- 하지만 Visual Recognition에서 불필요한 Attention은 '양날의 검'처럼 작용하고 여러 가지 결점이 존재
- 특히 Query Patch당 Self-Attention에 참여할 Key이 수가 너무 많으면 High Computational Cost를 가지고, Slow Convergence, OverFitting의 위험이 존재
- 지나친 Attention Computation을 피하기 위해 여러 방식으로 Attention을 진행
- 대표적으로 두 가지 어프로치가 있다. Swin Transformer는 Local Window에서 Attention을 제한하기 위해 Window-Based Local Attention을 진행
- Pyramid Version Transformer는 (PVT) Key와 Value Feature Map을 DownSampling 하여 계산량을 줄임
- 이러한 Hand-Craft Attention Pattern은 Data-agnostic 않으며 최적의 방식이 아님
- 관련이 있는 Key/Value은 삭제되고, 덜 중요한 Key/Value만 계속 유지될 수도 있음
- 이상적으로 하나를 기대해 볼 수 있는데, 주어진 Query에 대한 후보 Key/Value set을 Flexible 하고 각각의 개별 Input에 적응할 수 있는 능력을 생기게 해 Hand-Craft Sparse Attention Pattern의 문제를 완화 가능할 것
- 실제로 CNN의 Paper에서 Convolution Filter에 대해 Deformable Receptive Field를 학습하는 것은 Data에 대해 종속적으로 더 많은 정보가 있는 영역을 선택적으로 골라 효과적인 것인 것을 확인
- 가장 주목할 만한 연구인 Deformable Convolution Network는 다양한 Vision Task에서 인상적인 결과를 도출
- 이는 Vision Transformer또한 Deformable Attention Pattern을 적용하고자 하는 동기가 생김
- 그러나 이를 Naive하게 구현하는 것으 불합리하게 높은 Memory/Computational Cost를 초래
- Deformable Offsets에 의해 도입된 OverHead는 Patch수에 대해서 Quadratic
- 결과적으로 최근 다양한 연구에서 Transformer의 Deformable 메카니즘을 조사했지만, 높은 Computational Cost때문에 DCN과 같이 강력한 BackBone Network를 구성하기 위한 기본 요소로 선택한 사람은 없음
- 대신 Deformable Mechanism은 Detection Head에 채택되거나, 후속되는 Network에 대한 Patch를 Sampling 하기 위한 전처리 계층으로 이용
- 본 논문에서는 Image Classification 및 다양한 Dense Prediction Task을 위해 변형 가능 주의 변환기(DAT)라는 강력한 Pyramid Backbobne이 구성된 간단하고 효율적인 Deformable Attention Transformer(DAT)을 제시
- 전체 Feature Map에서 서로 다른 Pixel에 대한 서로 다른 Offset을 학습하는 DCN 방식
- 저자들은 여러 논문에 따르면 Global Attention은 일반적으로 서로 다른 Query에 대해 거의 동일한 Attention Pattern을 일으킴.
- 그러므로 Query-Agnostic offset의 몇가지 Group(모든 Query가 공유하는)을 학습하여 Key와 Value가 중요한 영역으 이동하도록함
- 이 설계는 Linear Space Complexity 유지하고 Transformer Backbone에 Deformable Attention Pattern을 도입
- 특히, 각 Attention Module에 대해 Reference Point은 먼저 Input Data 전체에서 Uniform Grid를 생성
- 그런 다음 Offset Network는 모든 Query Feature을 Input으로 사용후 모든 Reference Point에 대한 해당Offset을 생성
- 이러한 방식으로 후보 Key/Value이 중요한 Region으로 이동되므로 원래의 Self-Attention Module을 보다 높은 Flexibility와 Efficiency로 보강하여 보다 유용한 정보를 포착
- 요약하면, 저자들의 기여는 다음과 같음
- 저자들은 Visual Recognition을 위한 최초의 Deformable Self-Attention을 제안
- 여기서 Data Dependent Attention Pattern은 더 높은 Flexibility과 Efficiency을 제공
- ImageNet, ADE20K 및 COCO에 대한 광범위한 실험은 Model이 Swin-Transformer보다 훌륭하다는것을 증명
Related Work
Trasfomer Vision Backbone
- ViT가 도입된 이후에 개선 사항으로 Dense가 높은 Prediction Task와 Efficient Attention Mechanisms을 위한 Multi-Scale Feature을 학습하는 데 Focus를 맞춤
- 이러한 Attention Mechanisms은 보통 Window Attention, Global Token, Focal Attention, Dynamic Token Size등 다양
- 그 중에서도 추가적인 Inductive bias를 도입하기 위해 Convolution 연산을 Transformer model을 보완하는데 초점을 맞춘 연구들이 존재
- CvT같은 경우 Token Process에 Convolution을 채택하고, Stride Convolution을 이용하여 Self-Attention의 Computational Cost를 낮춤
- Convolution Stem(입력 이미지를 아주 aggressively하게 다운샘플링 하는 역할을 수행하는 네트워크)가 있는 ViT는 안정적인 Training을 위해 초기 단계에 Convolution을 추가
- CSwin Transformer는 Convolution Base로 Positional Encoding 기술을 채택하고 Downstream Task에 대한 개선 사항을 보여줌
- 이러한 Convolution Base 기술 중 많은 것이 잠재적으로 DAT 위에 적용되어 추가적인 성능 향상이 가능함
Deformable CNN and attention
- Deformable CNN은 Input Data에 따라 Flexible Spatial Location에 주의를 기울이는 메커니즘
- 최근에는 다양한 Vision Transformer에도 적용함
- Deformable DETR은 CNN Backbone 상단에 각 Query에 대해 적은 수의 Key를 선택하여 DETR의 Convergence 개선
- Key가 부족하면 Representaton Power가 제한되기 때문에 Deformable DETR 방식은 Vision에서 적합하지 않음
- 또한 Deformable DETR의 Attention는 단순히 학습된 Linear Projection에서 비롯되며 Key는 Query Token 간에 공유되지 않음
- DPT 및 PS-ViT는 Deformable Moduel을 구축하여 Visual Token을 세분화
- 구체적으로 DPT는 단계별로 Patch를 세분화하기 위해 Deformable Patch Embedding을 제안하고 PS-ViT는 Visual Token을 개선하기 위해 ViT Backbone 이전에 Spatial Sampling Module을 도입
- 하지만 위에 어느 것도 Deformable Attention을 Visual Backbone에 통합하지 않음
- 하지만 저자들의 Deformable Attention는 Visual Token 간에 공유된 일련의 Global Key를 학습하기 위해 강력하면서도 간단한 설계를 사용하며, 다양한 Vision Task을 위한 일반적인 Backbone로 채택될 수 있음
- 저자들의 방법은 또한 다양한 연구에서 효과적인 것으로 입증된 spatial adaptive mechanism으로 볼 수 있음
Deformable Attention Transformer
Preliminaries

- 먼저 최근에 Vision Transformer의 Attention Mechanism을 확인
- Feature Map을 Flattend하므로 x ∈ R N×C, MHSA Multi-Head Self Attetion, M Head개수, d = C/M
- σ(·) SoftMax, z (m) embedding output from the m-th attention head, q (m) , k(m) , v(m) ∈ R N×d
- Wq, Wk, Wv, Wo ∈ R C×C are the projection matrices
- Transformer block에는 MLP block with two linear transformation, 그리고 GELU Activation
- normalization layers and identity shortcuts, the l-th Transformer block is formulated
- LN is Layer Normalization
Deformable Attention
- Hierarchical Vision Transformer인 PVT, Swin Transformer는 과도하게 Attention을 하는것을 막기위해 노력
- 하지만 PVT의 Downsampling Technique은 Information loss를 일으키고, Swin Transformer의 Shift Window Attention은 Receptive Field가 순차적으로 느리게 커지는데, 큰 물체를 Modeling하는데 제약이 생김
- 따라서 관련 기능을 유연하게 Modeling 하기 위해 Data-Dependent Sparse Attention 필요하며, 이는 DCN에서 처음 제안된 Deformable Mechanism으로 이어짐
- 하지만 DCN의 방법을 Transformer Model에게 그대로 적용하는것은 어렵다
- DCN은 각 Feature Map의 각 요소는 Offset을 개별적으로 학습하여 HxWxC의 Feature Map의 3x3 Deformable Convolution은 3x3xHxWxC의 Space Complexity를 가진다
- Attention에 동일한 Mechanism을 직접 적용하면 Space Complexity가 Nq x Nk x C로 급격히 증가할 것이며, 여기서 Nq, Nk는 Query 및 Key의 수이며 일반적으로 Feature 크기 H W와 동일한 규모를 가지며 대략 Biquadratic Complexity
- Deformable DETR는 각 척도에서 Nk = 4로 더 적은 수의 Key를 설정하여 이러한 Overhead를 줄일 수 있었지만, 허용할 수 없는 Information loss 때문에 Backbone Network에서 그렇게 적은 Key를 관리하는 것은 안좋음
- 연구에 따르면 Visual Attention Model에서 서로 다른 Query가 유사한 Attention Map을 가지고 있다.
- 저자들은 효율을 위해 각 Query에 대해 Shared Shift Key와 Value을 가진 더 간단한 Solution을 선택
- 저자들은 구체적으로 Feature Map의 중요안 Region에 Guidance에 따라 Token간의 Relation을 효과적으로 Modeling하기 위해 Deformable Attention은 제안
- 이러한 Focused Region은 Offset Network에 의해 Query에서 학습된 Deformed Sampling Point의 Multiple Group에 의해 결정
- 그런 다음 Sampling된 Feature가 Key 및 Value Projection에 입력되어 Deformed Key 및 Value를 생성
- 마지막으로 Standard Multi-Head Attention는 Sampling된 Key에 대한 Query에 attend하고 Deformed된 Value에서 Feature을 집계하기 위해 적용
- 또한 Deformed Loaction의 Position은 Deformable Attention의 학습을 용이하게 하기 위해 보다 강력한 Relative Position Bias을 제공함(다음 Section)
Deformable Attention Module
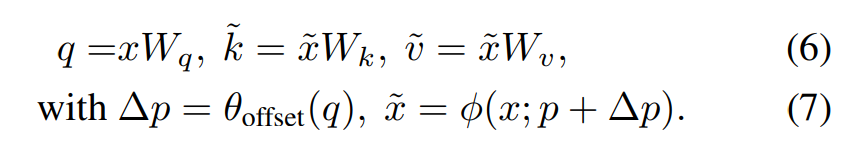
- Input Feature Map : x ∈ R H×W×C
- Uniform Grid Point : p ∈ R HG×WG×2, HG = H/r, WG = W/r. r = Factor
- values of reference points are linearly spaced 2D coordinates {(0, 0), . . . ,(HG − 1, WG − 1)}, And Normalize [−1, +1]
따라서 HG X WG Grid Size가 (-1,1)이됨, (−1, −1) indicates the top-left, (+1, +1) indicates the bottom-right corner. - Reference Point를 대한 Offset을 얻기 위해 Feature Map은 Linear로 Projected된다. q = xWq, 그리고 θoffset(·)이란 가벼운 Sub-Layer에 공급되어 ∆p = θoffset(q)가 생성
- Training 과정에서 Offset이 너무 커지는것을 방지하기 위해 미리 정의된 Factor s로 Amplitude를 조정, 즉
∆p ← s tanh (∆p). - 그런 다음 Feature이 Key 및 Value으로 Deformed Point의 Location에서 Sampling되고 Projection Matrics이 이어짐
- k˜ and v˜ represent the deformed key and value embeddings
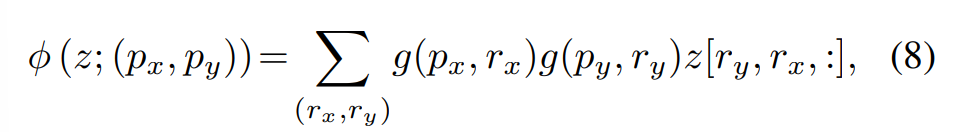
- 그 뒤에 8번 수식을 이용하여 Bilinear Interpolation
- g(a, b) = max(0, 1 − |a − b|)
- (rx, ry) indexes all the locations on z ∈R H×W×C
- g would be non-zero only on the 4 integral points closest to (px, py),
- it simplifies Eq.(8) to a weighted average on 4 locations.
Vision Transformer With Deformable Attention.pdf
2.39MB
Experiments
- AdamW, 300Epochs, Cosine Learning Rate Decay
- RandAugment, Mixup, CutMix
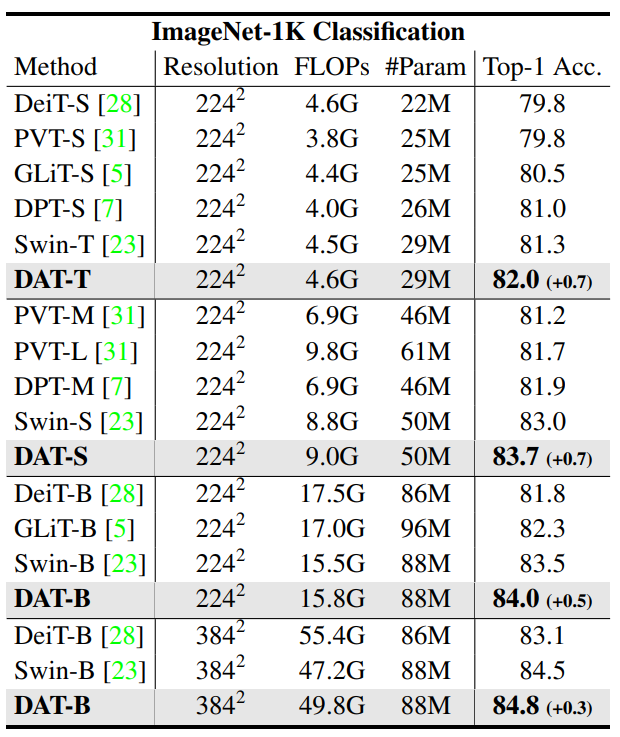
- Tiny, Small, Base에서 모두 기존 ViT 모델보다 좋은 성능을 확인
- 같은 Scale의 Swin Transformer보다 FLOPs가 약간 증가
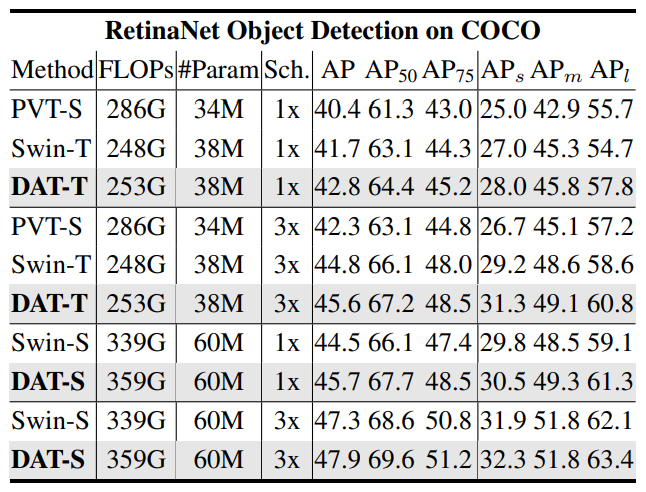
- DAT를 BackBone으로 하여 RetinaNet에서 Object Detection 성능 확인
- ImageNet 으로 Pretrained(300Epochs)
- 최종 결과로 Tiny, Scale, Base에서 다른 PVT, Swin보다 좋은 결과를 얻음
- 같은 Scale의 Swin Transformer보다 FLOPs약간 증가
- DAT를 이용하면 Small, Large Object Detection 성능이 향상
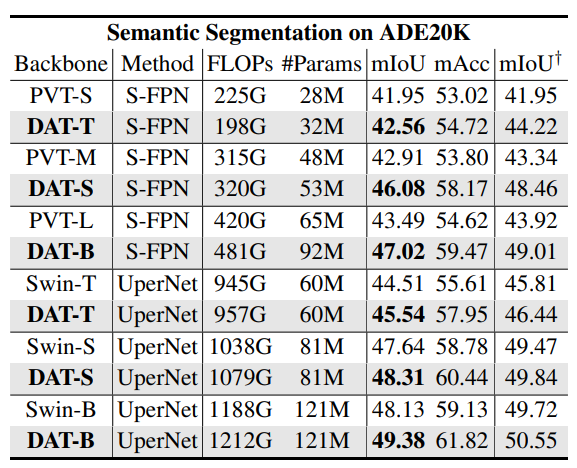
- DAT를 BackBone으로 하여 Semantic Segmentation 성능 확인
- SemanticFPN, UperNet
- PVT, Swin Transformer 보다 약간 증가한 Flops에서 mIoU
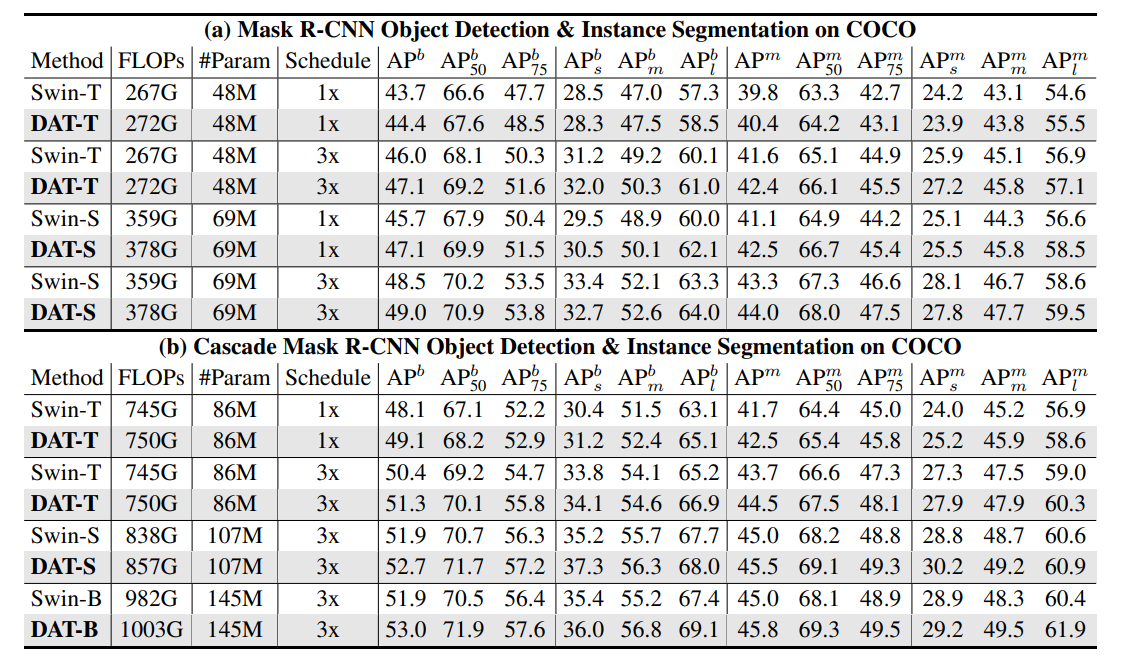
- DAT와 Swin Transformer을 BackBone으로 하는 Mask, Cascade Mask R-CNN 결과 비교
- 모든 경우에서 개선된 결과를 얻었고, BackBone으로 가치가 큼
Ablation Study
Visualization

- COCO Validation Set에서 Attention Score가 높은 Key Feature을 시각화( Score가 높을수록 원이 커지게됨
- Object Detection에서 중요한 부분과 경계에 대해 Score가 높게 나옴(얼굴, 동물, 손)
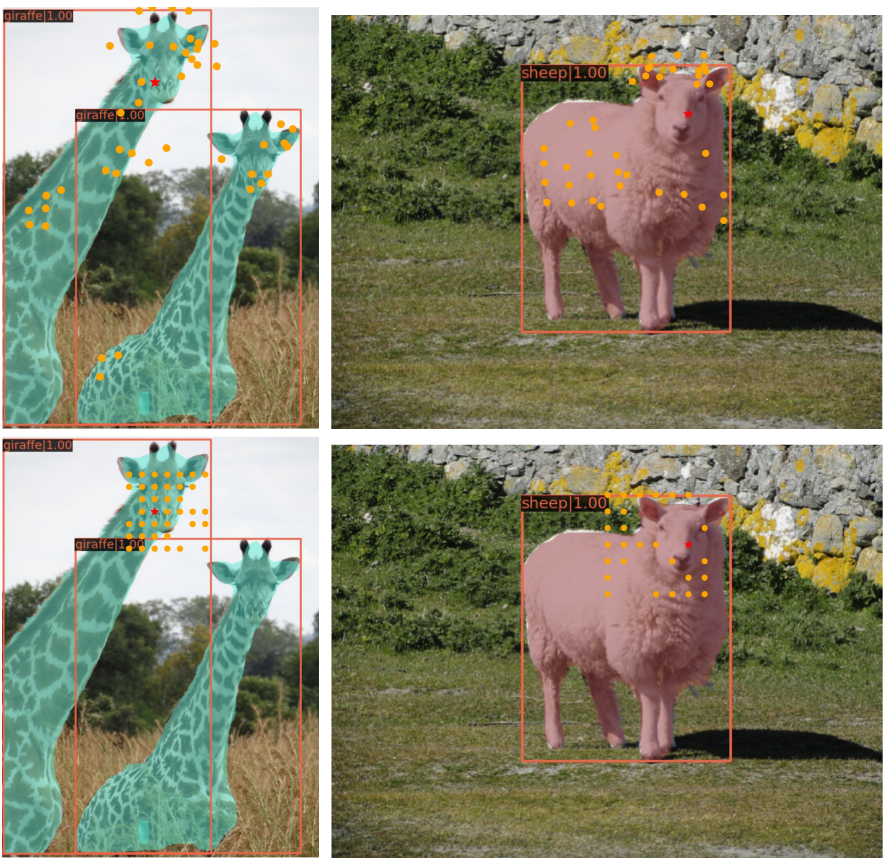

- 빨간색 Query Point에 대해 Attention Score가 높은 Key를 시각화
- Swin-Transformer의 경우 고정된 Key Point가 나오는 반면, DAT는 Object의 주요 위치로 이동