* 공부한 내용 뇌피셜로 정리 *

Non max suppression 기법은 Object detection 알고리즘에서 사용되는 방법중 하나 입니다.
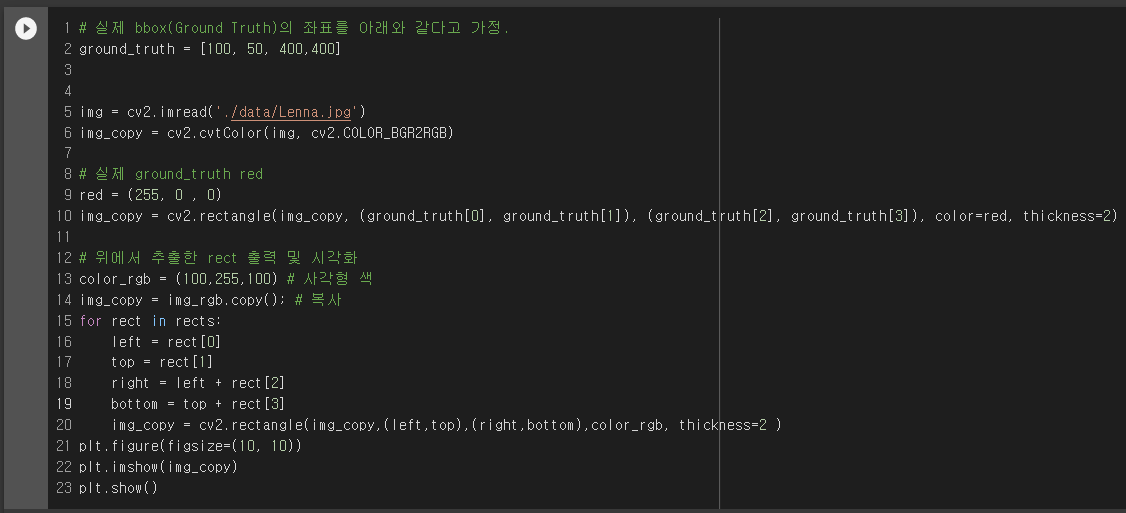
Object detection은 있을만한 위치를 모두 예측 하므로 위에 그림과 가이 겹치는 bounding box가 많아 집니다.
이렇게 겹치는 bounding box가 많을때 비슷한 것을 제거하고 가장 적합한 것을 선택하는 기법입니다.
NMS수행 로직은 어렵지 않습니다.
1단계
Object detected 된 bounding box에서 사용자가 설정한 confidence threshold이하인 bounding box는 모두 제거 합니다. 즉 이용자가 threshold를 0.6 으로 정하면 0.6 이하는 모두 제거합니다.
2단계
confidence score별로 내림차순을 적용합니다.
3단계
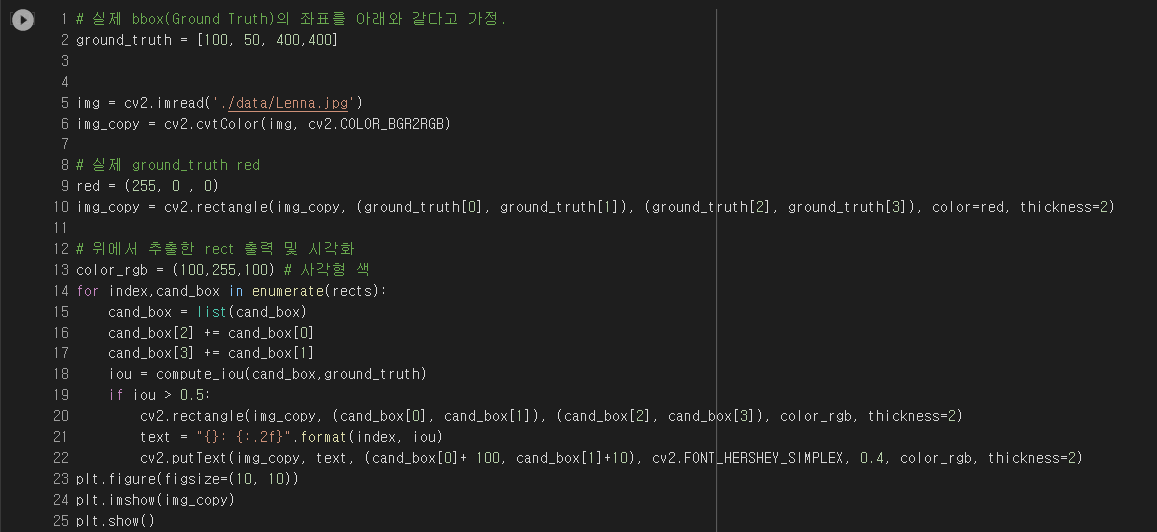
confidence score가 높은 놈들과 겹치는 다른 box는 모두 제거 하는데, 이용자가 정한 특정한 IOU Threshold 이상인 것들은 모두 제거 합니다. 즉 IOU값은 0.5로 정하면 0.5 이상은 모두 제거합니다.
4단계
남아있는 BBOX를 선택합니다.
'AI 공부 한 것' 카테고리의 다른 글
| [논문 리뷰] AlexNet(2012) 논문리뷰 (ImageNet Classification with Deep ConvolutionalNeural Networks) (0) | 2022.01.11 |
|---|---|
| [컴퓨터 비전] object detection 성능 평가 방법 (mAP, Precision, Recall) (3) | 2021.12.29 |
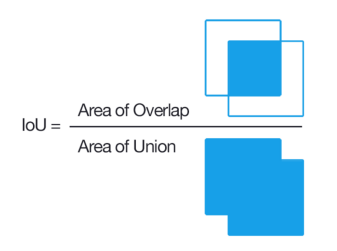
| [컴퓨터 비전] IoU(intersection over union) (0) | 2021.12.28 |
| [컴퓨터 비전] Sliding window 대한 내용, Selective Search 사용 및 시각화 (0) | 2021.12.24 |
| [12/22] 인공지능 공부한내용 (0) | 2021.12.22 |