https://arxiv.org/abs/2211.05778
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state. This work presents a new large-scale CNN-based foundation model, termed
arxiv.org
Abstract
- 최근 몇년간 Large Vision Transformer가 크게 발전한 것과 비교하면 cCNN을 기반으로 한 Large Scale Model을 거의 연구가 안됨
- 해당 논문에서는 ViT와 같은 Parameter와 Training Data를 증가시켜 이득을 얻을 수 있는 Large Scale CNN-Based Foundation Model InternImage를 소개
- Large Dense Scale Kernel을 이용하는 최근에 접근방식과 달리 InternImage는 Deformable Convolution을 Core Operator로 설정하였고, Detection, Segmentation과 같은 Task에서 필요한 Effective Receptive Field를 가지고, Input및 Task Information에 의해 조정되는 Adative Spatial Aggregation을 가지고 있음
- 결과적으로 InternImage는 기존 CNN의 엄격한 Inductive Bias를 줄이고, ViT와 같은 Large-Scale Data에서 대규모 Parameter로 더 강하고 강력한 Pattern을 학습할 수 있게 함
- 저자들은 ImageNet, COCO, ADE20K에서 좋은 성능을 가지고 SOTA에 달성
- ViT를 능가하는 CNN이 가능하다는 것을 입증
Introduction
- Transformer, ViT는 NLP, Vision 분야를 휩쓸어서 모든 연구의 Primary Choice, Large Scale Vision Foundation Model의 기초가 됨
- ViT를 확장하여 아주 큰 Model을 만들고 다양한 Task에서 사용됨(Classification, Detection, Segmentation)
- 이러한 결과는 대규모 Parameter 및 Data 시대에 CNN이 ViT보다 떨어진다는 것을 시사함
- 하지만 저자들의 CNN Based Foundation Model이 유사한 Operator/Architecture-Level Design, Scaling-Up Parameter, Massive Data를 장착하면 ViT보다 비슷하거나 더 좋은 성능에 달성할 수 있다고 주장

- CNN과 ViT 사이의 Gap를 해소하기 위해 먼저 두 가지 측면에서 차이점을 요약
- Operator Level에서 보면 ViT는 Long-range Dependence와 Adative Spatial Aggregation(적응적으로 공간영역을 집계)을 가짐, Flexible한 MHSA의 이점을 활용하여 ViT는 Large-Scale Data에서 CNN보다 더 강력하고 강력한 Representation을 학습할 수 있음
- Architecture 관점에서 보면 MHSA외에도 ViT에는 Layer Normalization, FC-Layer, GELU 등과 같이 Standard CNN에는 포함되지 않은 고급 구성 요소가 있음
- 최근 연구가 Fig 1(c)에 표시된 것 처럼 매우 큰 Kernel(31x31 https://github.com/DingXiaoH/RepLKNet-pytorch)를 가진 Dense Convolution을 사용하여 CNN에 Long-range Dependence를 도입하려는 의미있는 시도를 했지만, 성능 및 Model Size 측면에서 Large-Scale ViTs와는 격차가 존재
- 해당 연구에서는 Large-Scale Parameter 및 Data를 효율적으로 확장할 수 있는 CNN Based Foundation Model을 설계하는데 집중
- 구체적으로 저자들은 Flexible Convolution인 DCN에서 시작함
- Transformer와 유사한 구조의 맞춤형 Block Level 및 Architecture Level Desgin을 채택하여 InternImage라는 새로운 Backbone을 만듦
- Fig 1에서 볼 수 있듯이 31x31과 같이 매우 큰 Kernel를 이용하여 개선한 CNN과는 달리 Internimage는 Core Operator로 Window size가 3x3인 Dynamic Space Convolution
- 주어진 Data에 대해서 적절한 Receptive Field(Long or Short Range)를 Dynamic하게 학습할 수 있는 Sampling Offset
- Sampling Offset은 Modulation Scalars에 대해 적응적으로 조정되어 ViT와 같은 Adative Spatial Aggregation을 달성, Standard Convolution의 과도한 Inductive Bias를 감소
- Convolution Window는 일반적으로 3x3이며 Large-Dense Kernel로 인한 Optimization Problem과 Expensive Cost를 방지

- 앞서 언급한 설계를 통해 제안된 InternImage는 큰 Parameter Size로 효율적으로 확장하고 Large-Scale Dataset에서 더 강력한 Representation을 학습하여 광범위한 Vision Task에서 Large-Scale ViT와 비슷하거나 훨씬 더 나은 성능을 얻음, 저자들의 기여는 다음과 같음
- Large-Scale CNN-Based Foundation Model InternImage를 제안
- 저자들이 알기를 1B Parameter와 400M 이상의 Training Image로 효과적으로 확장하고 SOTA ViT와 비슷하거나 심지더 더 나은 성능을 보여주는 최초의 CNN
- Convolution Model이 대규모 Foundation Model연구를 위해 탐색할 가치가 있는 방향이기도 함을 보여줌 - 개선된 3x3 DCN Operator를 사용하여 Long-Range Dependencies와 Adative Spatial Aggreation을 도입하여 CNN을 Large-Scale Setting에서 성공적으로 확장
- Operator를 중심으로 Basic Block구축
- Stack Rule 및 Scailng 전략을 탐구
- 이러한 설계는 Operator를 효과적으로 사용하여 Model이 Large Scale Parameter 및 Data로부터 이득을 얻을 수 있게함 - Image Classification, Object Detection, Instance and Semantic Segmentation에서 Model을 평가하고 크길르 30M에서 1B, Data는 1M에서 400M까지 확장하여 SOTA CNN 및 Large-Scale ViT와 비교
- 여러 Size의 Model이 ViT, CNN과 비교하여 SOTA에 달성
Related Work
- Vision Foundation Models
- Large-Scale Dataset과 Computation Resource를 사용할 수 있게 된 후에 CNN은 Visual Recognition에서 주목
- AlexNet, VGG, GoogleNet, ResNet, EfficientNet 등 다양한 깊은 Network 등장
- 이런 Model 설계 이외에도 DCN, Depthwise Separable Conv등 다양한 Method 연구가 진행
- 최근 몇년간에는 Transformer Based Model이 초점에 맞춰짐
- ViT는 가장 대표적인 Model로 Global Receptive, Dynamic Spatial Aggregation을 가짐
- 그러나 ViT에 대한 전 세계적인 관심은 Large Feature Map에서 Downstream Task에 적용을 제한하는 Computation / Memory Complexity으로 인해 어려움을 겪고 있음
- 이를 해결하기 위해 PVT, Linformer 같이 Key & Value를 Downsampling하거나, DAT와 같이 Deformable Attention을 이용함
- 이외에도 HaloNet, Swin Transformer는 Local Attention 메카니즘과 Shfited Window를 통해 정보를 전송 - Large-Scale Models
- Model을 확장하는 것은 NLP 영역에서 잘 연구된 Feature Representation을 향상시키는 중요한 전략
- NLP분야에서 성공에 영감을 받은 여러 연구지는 처음으로 ViT에 2B 의 Parameter로 만듬
- Swin Transformer를 3B로 만든 연구도 존재
- 일부 연구자들은 다양한 수준에서 ViT와 CNN의 장점을 결합하여 Hybrid-ViT를 만들기도 함
- 그러나 CNN-Based Foundation Model에 대한 연구는 Parameter와 성능 측면에서 Transformer 기반에 비해 낮음
- 최근에 CNN Kernel의 크기를 늘리고 Depthwise-Separable로 가는 방향도 있었지만 여전히 ViT와는 격차가 존재
- 본 연구에서는 ViT에 필적하는 대규모, 효율적인 CNN기반 Based Foundation Model의 개발이 목표
Proposed Method
- Large-Scale CNN-Based Foundation Model을 설계하기 위해 저자들은 Flexible Convolution , 즉 DCNv2를 참조함
- 그리고 몇 가지 조정을 통해 요구사항에 더 잘 맞도록 DCNv3를 설계
- 그런 다음 Deformable Convolution Operator를 현대 Backbone에 사용되는 Block 설계 방식과 결합하여 Basic Block으로 이용
- 마지막으로 DCN 기반 Block Stack 및 Scailing 원리를 탐구하여 대규모 Dataset에서 Model이 더 잘 학습되도록 함
Deformable Convolution v3
- Convolution vs MHSA
- 이전 연구에서 CNN과 ViT의 차이점에 대해 다양하게 논의
- InterImage의 Core Operator를 결정하기 전에 먼저 Regular Convolution과 MHSA의 차이에 대해 설명
(1) Long-Range Dependencies
- Effective Receptive Field가 큰 Model은 대개 Downstream Vision Task에서 더 잘 수행된다는 것이 오랫동안 인식됨
- 3x3 Regular Convolution에 의해 Stacked CNN은 실질적인 Effective Field는 상대적으로 작음
- Very Deep Model에서도 CNN Based Model은 Long-Range Dependencies를 얻을 수 없음
(2) Adaptive Spatial Aggregation
- Weight가 Input에 의해 Dynamic하게 조정되는 MHSA와는 다르게 Regular Convolution은 Static Weight를 가지고 2D Locality, Neightborhood Structure, Translation Equivalence 특성을 가진 Operation
- Bias가 높은 특성을 이용하여 Regular Convolution Model은 ViT에 비해 빨리 수렴되고 Training Data가 덜 필요할 수 있지만 CNN이 Web-Scale의 Large-Scale Data에 정보를 학습하는 것을 제한하기도 함
- Revisiting DCNv2 (아래의 Image 참조)
- 저자들은 ∆pk을 이용하여 Long-Range Dependencies를 Capture할 수 있고 Short-Range까지 커버가 가능하다는 주장을 함
- Adaptive Spatial Aggregation의 경우 Sampling Offset ∆pk와 Modulation ∆mk가 모두 학습할 수 있어 MHSA와 유사한 특성을 제안한다고 생각(Static Weight가 아니라 Convolution 취할때마다 Weight를 변경시킴, MHSA와 유사, Sigmoid로 Attend하는 값을 Scaling)


- Extending DCNv2 for Vision Foundation Models
- 일반적으로 DCNv2은 Regular Convolution의 확장으로 이용되고,일반 Convolution Pretrained 된 Weight를 Load하여 더 나은 성능을 위해 Fine Tuning
- 이는 From Scratch로 Trainijg 해야하는 Large-Scale Vision Model에는 적합하지 않음
- 해당 논문에서는 이 문제를 해결하기 위해 3가지 측면에서 DCNv2 확장 - (1) Sharing weights among convolutional neurons
- 일반 Convolution과 유사하게 DCNv2는 각 Convolution 뉴런마다 독립적인 Weight를 가짐(3x3 Kernel의 경우 9개의 Weight 당연한 이야기임)
- 그러므로 Parameter와 Memory Complexity가 Sampling point 숫자에 대해 Linear하게 늘어남(3x3 Kernel은 9, 5x5 Kernel은 25) 이럴 경우에 DCN을 이용하여 Large-Scale Model을 만들기에는 효율적이지 않음
- 이에 따라 Depthwise Separable Convolution에서 아이디어를 빌려와 가중치 Wk를 Depthwise, Pointwise 로 분리
- Depthwise Part는 location-aware modulation scalar mk가 담당하고, Pointwise Part는 shared projection weights w among sampling points로 진행 - (2) Introducing multi-group mechanism
- Multi-Group Design은 Group Convolution에서 처음 등장했고, MHSA의 Transformer 방식에서 Multihead Attention 형식으로 등장
- Adative Spatial Aggregation과 함께 작동하며 서로 다른 Position의 다른 Representation Sub-Space의 풍부한 정보를 효과적으로 학습
- 이에 영감을 받아 저자들은 Spatial Aggregation을 G그룹으로 분할, 각 Group은 ∆pgk라는 Sampling Offset, mgk 라는 Modulation Scale을 가지고 있으므로 서로 다른 Group에서는 MHSA처럼 서로 다른 Spatial Aggregation Pattern을 가질 수 있으므로 Downstream Task에서 강력한 Feaute를 제공 - (3) Normalizing modulation scalars along sampling points
- 기존의 DCNv2에서는 Modulation을 계산할 때 Sigmoid를 이용함
- 그러므로 Sigmoid 함수의 특성으로 Modulation Scalars를 [0,1]범위에 있고, 모든 Sample Point들의 Modulation Scalar 합은 0 ~ K 까지 다양하여 Stable하지 않음(값이 튐)
- 이렇게 하면 Large-Scale Parameter와 Data로 Training할 때 DCNv2 Layer에 unstable gradients로 이루어짐
- Unstable Problem을 완화하기 위해 Sigmoid를 이용하는 것이 아닌 Softmax를 이용하여 값을 Normalization
- 이럴 경우에 MHSA처럼 Modulation Value가 안정이 됨, Large-Scale Model Training시에 안정적인 결과를 생성 - 위의 (1,2,3)에서 설명한 변경점들을 모두 합치면 DCNv2 수식에서 아래와 같은 DCNv3를 도출할 수 있음

- G는 Group의 숫자(Group Convolution의 개수), K는 Sampling Point의 개수
- W ∈ R C×C' , C' = C / G, Group Convolution시에 (1) 에서 설명한 방식대로 하나의 Channel에서 하나의 가중치를 곱
- mgk ∈ R Modulation Scalar k-th Sampling Point의 g-Group, K개의 Point이므로 K개로 Softmax
- ∆pgk Sampling Point Offset
- 일반적으로 DCNv3는 DCN Series의 확장으로서 3가지 장점을 가지고 있음
- (1) 이 Operator는 Long-Range Dependencies 및 Adative Spatail Aggregation 측면에서 Regular Convolution보다 장점이 큼
- (2) 일반적인 MHSA 및 밀접한 관련이 있는 Deformable Attention과 비교하여 해당 Operator는 Convolution Inductive Bias를 상속하여 더 적은 Training Data와 Time으로 모델을 더 효율적으로 만듬
- (3) 해당 연산자는 Sparse Sampling을 Base로 하므로 Computational and Memory Efficient가 MHSA나 31x31 Kernel을 Re-Parameterizing 한 것보다 좋음
- 추가적으로 Sparse Sampling 덕분에 DCNv3는 3x3 Kernel을 이용하여 Long-Range Dependencies를 Capture가능하고, 최적화하기 쉽고 Large Kernel에 사용되는 Re-Parameterizing같은 Auxiliary 기술을 방지함
InternImage Model

- DCNv3는 Core-Operator, 하지만 새로운 문제가 있음
- 엔지니어링에서는 단순하게 Network를 쌓을 수 있는것이 중요함(3x3 Convolution을 Stack한 VGGNet과 같이)
- 이에 따라 Core-Operator를 이용하여 Model을 효과적으로 구축하는 방법에 대한 연구가 필요
- Basic Block과 다른 Integral Layer를 제시하여 맞춤형 Stack전략을 탐색하여 InternImage를 제안
- 또한 Model에 대한 효율적인 Scailing Rules를 제안
- Basic Block
- 기존 CNN에서 널리 사용되는 BottleNeck과는 달리 저자들의 방식은 LN, FFN, GELU를 포함한 ViT에 더 가까움
- 이런 설계는 다양한 Vision Task에서 효과적인 것을 입증
- Basic Block의 설계는 Fig3과 같으며 Core Operator는 DCNv3이고, Offset과 Modulation은 Depthwise Separable Convolution을 통해 Input Featue X에 전달
- 다른 구성 요소는 Transformer와 유사함 - Stem & Downsampling Layer
- Hierarchical Feature Map을 얻기 이해 Convolution Stem 및 Downsampling Layer를 사용하여 Feature Map의 Size를 다른 Scale로 조정
- 우선 Stem Layer를 보면 Stage1 이전에 배치되어 Input Resolution이 4배 감소
- 두개의 3x3 Convoltion, Stride 2, padding 1, LN, GELU를 이용, 첫 Convolution 의 Output Channel은 Second의 절반
- 비슷하게 Downsampling Layer에는 Stride가 2이고, Padding=1인 3x3 Convolution, LN Layer가 하나씩 있음
- 두 Stage 사이에 위치하고 Input Feature Map을 2배 DownSampling, Channel 은 Upsampling됨 - Stacking Rules
- Stacking Rules Process를 명확히 하기 위해 InternImage의 Hyperparameter를 아래와 같이 나열
- 저자들의 Model은 4개의 Stage로 구성되는데, 각 Stage마다 아래와 같은 Hyperparameter를 모두 정하게하면 총 12개의 Parameter를 골라야 하므로 Search Space가 너무 커지는 단점이 존재
- 이를 위해서 4개의 Design Rules을 정함(그림3)
- (1) C1이 나머지 Stage의 Channel Number를 결정(C1)
- (2) 두번째 Rule은 모든 Stage에서 같은 Group숫자를 가짐 (C' 전달)
- (3) AABA Rule을 통해 1,2,4 Stage는 같은 숫자의 Layer, 3는 다른 숫자의 Layer(L1, L3)
- (4) L3가 무조건 L1보다 크거나 같아야 한다
- 이런 설정으로 Search Space를 줄여서 효율적으로 탐색하여 Origin Model은 (64, 16, 4, 18)로 Setting

- Scaling Rules
- Base Model인 Origion Model을 참조하여 저자들은 Scailing Rule을 정했는데, EfficientNet에서 제안된 방식을 활용
- 두개의 Scaling Dimension을 고려하는데 Depth = (i.e., 3L1+L3) and Width C1, And Two Dimension using α, β and Composite Factor φ
- Scaling Rule은 아래의 그림과 같음, 1.99는 InternImage에 한정되고, Model의 Width를 두배로 늘리기 위해 일정하게 유지하여 계산됨
- 저자들의 실험으로 α = 1.09 및 β = 1.36인것을 확인 했고, 이를 기반으로 T/S/B/L/XL/H를 구성


Experiment


- Image Classification
- InternImage-T/S/B ImageNet-1k에서 From Scratch로 300Epochs
- InternImage-L/XL ImageNet-22k 90Epochs -> ImageNet-1k 20Epochs
- 이전 CNN, ViT SOTA Model에 비해 좋은 결과를 얻음(격차도 크게 존재)
- ‡ = ImageNet-22k Pretrain, # Extra Large Scale Pretraining JFT-300M, FLD-900M


- Object Detection & Instance Segmentation
- 1x 12Epochs, 3x 36Epochs, Pretrained Weight를 이용
- 모든 경우에 최고의 AP를 얻음
- SOTA Detector들과 비교해도 다른 것들에 비해 가벼운 Parameter로 SOTA에달성

- Semantic Segmentation
- UperNet을 이용하여 Test, 마지막에는 Maks2Former를 이용
- 가벼운 Parameter로 높은 mIOU를 얻음
Ablation Study
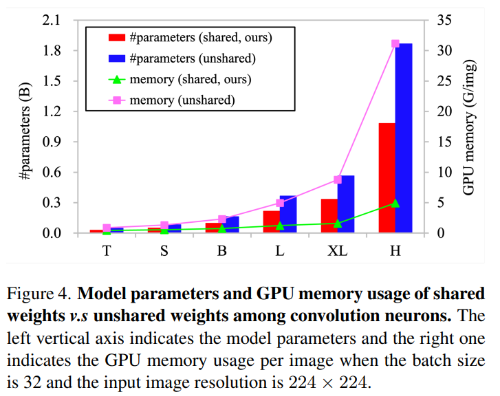

- Sharing weights among convolution neurons matters
- Large Scale Model은 Parameter와 Memory Cost에 민감하게 반응함, Hardware Limitation이 존재
- 이런 문제를 해결하고자 저자들은 Shared Weight Convolution을 이용
- Fig4를 보면 Shared Weight를 이용하는 경우와 이용하지 않는 경우에 대한 결과를 확인
- Shared Weight를 이용하는 경우가 훨씬 효율적인것을 알 수 있고, Table 6을 보면 이용하는 것과 이용하지 않는것에 큰 차이가 없음을 알 수 있음 - Multi-group spatial aggregation brings stronger features
- 저자들의 Model은 Transformer의 MHSA와 같이 다양한 Head를 이용하는 것 처럼 다양한 Sub-Space학습이 가능
- 그림 5와 같이 동일한 Query Pixe(별)에서 서로 다른 Group의 Offset이 서로 다른 영역을 보는 것을 알 수 있음
- 그리고 Table6을 봐도 MultiGroup 방식을 적용하는 것이 더 좋은 성능을 가져옴
- Model이 깊어질수록 effective receptive field(ERF)가 점점 증가함, 이런 현상은 Vanila ViT와는 다름

Conclusion & Limitations
- Image Classification, Object Detection 및 Semantic Semgnation과 같은 다목적 비전 Task에서 강력한 Model인 InternImage 소개
- DCNv3를 개발하고 Block, Stack, Scailing Rule을 개발
- 여러 Dataset에서 CNN이 여전히 좋은 선택이라는 것을 보여줌
- 아직 개발 초기이므로 더욱 개선될 수 있다고 생각