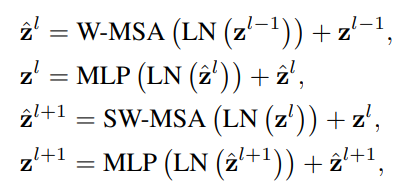https://arxiv.org/abs/2106.13230
Video Swin Transformer
The vision community is witnessing a modeling shift from CNNs to Transformers, where pure Transformer architectures have attained top accuracy on the major video recognition benchmarks. These video models are all built on Transformer layers that globally c
arxiv.org
Abstract
- Pure Transformer Architecture가 Video Recognition Benchmark에서 좋은 Accuracy를 보임
- 이런 Video Model Transformer Model은 Spatial, Temporal Dimension을 Global하게 연결
- 해당 논문에서는 Video Transformer에서의 Locality Inductive Bias를 옹호
- 이는 Global로 Attention을 하는 것에 비해서 더 나은 Speed-Accruacy의 Balance가 지켜짐
- 저자들의 Video Architecture는 Image Domain을 해결하기 위해 설계된 Swin Transformer를 적용하는 동시에 Pretrain된 Image Model의 힘을 활용
- 다양한 Test에서 SOTA에 달성, Less Pretraining, Smaller Model Size
Introduction
- CNN Based Backbone 구조는 긴 기간동안에 Computer Vision분야에 지배적이였지만, ViT(globally models spatial relationships on non-overlapping image patches)의 등장으로 다양한 Task에서 Transformer를 이용, 이는 Video Recognition Task도 해당함
- 이전 Video Task의 CNN Model은 단순히 Temporal Axis로 확장한 형태로 진행, 이런 Joint SpatioTemporal Modeling은 Computational Cost가 경제적이지 않고, Optimize가 쉽지 않음
- 이를 해결하고자 Factorization(Spatio Temporal을 분리)해서 더 나은 Speed와 Accuracy를 달성함
- Transformer Base의 Video Recognition의 첫 시도는 ViViT와 TimeSformer에서 나온 Factorized Encoder, Factorized Self-Attention -> 연산량을 낮추고, 모델의 크기를 줄임
- 해당 논문에서는 Pure Transformer Backbone 구조를 이용하는 Video Recognition을 소개, Factorized Model보다 좋은 효율을 가짐
- Spatio Temporal Locality(Spatiotemporal Distance가 가까운 Pixel이 더 관련있는)를 가지는 Video의 특성을 활용
- 이 특성으로 인해 Full SpatioTemproal Attention은 Local에서 계산된 Self-Attention에 의해 근사 가능
- 저자들의 구현은 Swin Tranformer의 접근 방식은 SpatioTemproal에 맞게 바꿈
- Swin Transformer는 Spatial locality뿐만 아니라 Translation Invariance를 이
- Video Swin Transformer라고 불리는 Model은 원래 Swin Transformer의 hierarchical structure를 이용하고, Local Attention의 범위를 Spatial에서 SpatioTemporal 영역까지 확장
- Non-Overlapping Window에서 Local Attention이 계산됨에 따라 원래 Swin Transformer의 Shifted Window 메커니즘도 Temporal 영역까지 확장
- Swin Transformer를 이용하기 때문에 ImageNet-21k으로 Pretrain하고, 이를 이용해 초기화 가능
- Backbone의 Learning Rate는 Head에 비해 0.1배로 진행함
- 결과적으로 Backbone은 새로운 Video Data에 맞추는 동안 Pretrain된 Parameter와 Data를 느리게 잊어 더 나은 일반화 방법으로 이어짐, 이런 Pretrain된 Parameter를 이용하는 방법을 찾음
- 이런 방법으로 여러 Task에서 SOTA에 달성
Related Work
- CNN and Variants
- CNN은 긴 기간동안 Computer Vision 분야에 Standard
- 3D Modeling을 하기 위해서는 단순히 Temporal 축으로 차원을 늘려서 진행하는 CNN방식을 이용
- 하지만 Small Receptive Field를 가짐, 이를 넓히기 위에서는 Network Depth를 늘려야 함
- 이는 Parameter증가, Computational Cost 증가라는 문제가 야기됨, 이로 인해 Self-Attention Mechanism이 Vision분야에 주목을 받음 - Self-Attention / Transformers To Complement CNNs
- NLNet는 Visual Recognition Task를 해결하기 위해 Self-Attention을 채택한 최초의 방식
- GCNet, DNL등 다양한 Task에서 Long Range Dependencise를 Modeling하기 위해 CNN에 보완적인 방식
- 저자들의 방식은 Self-Attention의 힘을 이용하여 우수한 성능으로 이어짐 - Vision Transformers
- ViT의 시작으로 Computer Vision분야의 Backbone으로 CNN에서 Transformer로 넘어감
- DeiT는 Several Traning Strategies 를 통합하여 적은량의 Data로도 학습이 가능하도록 한 방식
- Swin Transformer는 Locality, Hierarchy, Translation Invariance라는 Inductive Bias를 가짐
- Swin은 이로인해 General Purpose Backbone으로서 Image Recognition Task에 주목을 받음 - Image -> Video
- Image Transformer의 큰 성공으로 Video Based Recognition Task에 대한 연구도 진행됨
- VTN은 Pretrain된 ViT위에 Temporal Attention Encoder를 추가, 좋은 성능을 얻음
- TimeSformer는 5가지의 다양한 Attention 방식을 연구
- ViViT는 Pretrain 된 ViT Model에 대한 Space, Time Attention에 대해 다양한 Factorized Design을 보여줌
- 여러 연구들은 모두 Global Self-Attention Module을 Base로 함
- 이 논문은 Spatio Temporal Locality를 조사한 다음, spatiotemporalLocality bias를 가지는 Video Swin Transformer가 기존 Video Transformer의 성능을 능가 한다는것을 입증
Video Swin Transformer

- 3.1 Overall Architecture
- Tiny Version을 시각화 한 것
- Input 으로 T x H x W x 3, T는 Frame, H x W x C는 Image
- Video Swin Transformer는 3D Patch를 다루는데, Size는 2 x 4 x 4 x 3
- 3D Patch Partitioning Layer에서는 T / 2 x H / 4 x W / 4 개의 3D Token을 얻을 수 있음, Channel은 2 x 4 x 4 x 3 = 96
- 이를 Linear Embedding Layer를 적용하여 Arbitrary Dimension인 C로 투영 - 해당 저자들은 Temporal Dimension을 따라 Down Sampling을 진행하지 않음
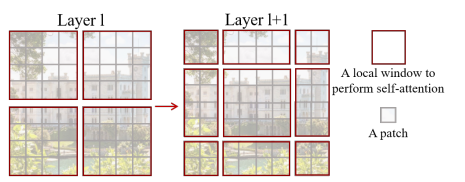
- 4-Stage로 구성되고 각 Stage에서 Patch Merging Layer에서 2x Spatial Down Sampling을 진행하는 Original Swin Transformer와 비슷한 구조
- Patch Merging Layer는 2x2 Spatially Neighboring Patch Group의 Feature를 연결하여, Linear Layer를 적용해서 4C가된 Channel Dim의 크기를 2C로 투영
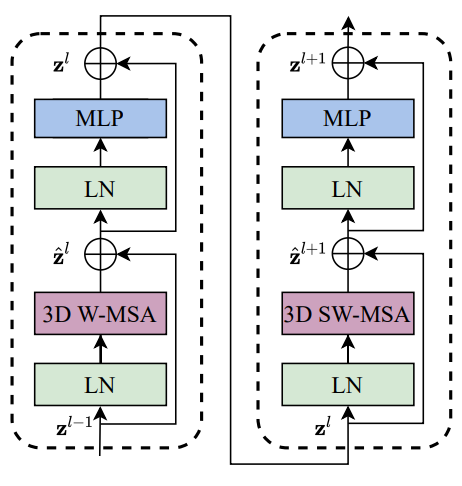

- Video Swin Transformer Block의 Major Component는 W-MSA, SW-MSA는 3D로 바꾼 것
- 다른 Component는 바꾸지 않음 - 3.2 3D Shifted Window Based MSA Module
- Image와 비교해서 Video는 Temporal Dimension이 존재해서 아주 많은 Input Token을 가지게됨
- 그러므로 Global Self-Attention Module은 Video Task에 적합하지 않음(Video는 상당한 Computation, Memory Cost가 발생함)
- Swin Transformer의 Locality Inductive Bias가 Video에도 효과적

- Multi-head self-attention on non-overlapping 3D windows
- Non-Overlapping 2D Window MSA는 Image Recognition Task에서 effective and efficient가 뛰어남
- 저자들은 Video Input에 이것을 단순하게 확장
- Input으로 T' × H' × W' 3D Token이 들어오고 P x M x M 3D Window가 주어지면, Window는 Non-Overlapping 방식으로 Video Input을 균일하게 분할
- 즉 Input token은 T' / P x H' / M x W' / M 으로 변함
- Figure 3를 보면 Input Token가 8 x 8 x 8 이고, Window Size가 4 x 4 x 4 일 총 8개의 Window로 분할됨 - 3D Shifted Windows
- Self-Attention Mechanisim은 Non-Overlapping 3D Window에 적용됨
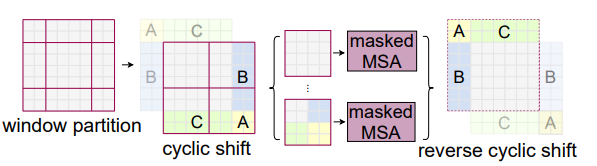
- 하지만 Swin 에서 설명한 것처럼 다른 Window와의 Connections이 부족하고, 이는 Representation Power가 Limit
- 이를 해결하기 위해 저자들도 Swin에서 이용된 것처럼 2D Shited Mechanism을 3D로 확대, 이런 방식은 Window간의 Connection을 이용하고, Non Overlapping Window Self-Attention의 효율적인 계산을 유지
- T' x H' X W' 3D Token, 3D Window P x M x M, 연속된 두개의 Layer에서 각 Window내에는 [T'/P] x [H'/M] x ['W'/M]
- 1-Layer에서 Self-Attention을 취하고 (P/2, M/2, M/2) 만큼 오른쪽 아래방향으로 Shift
- Figure3을 보면 Input Size = 8 x 8 x 8, Window Size = 4 x 4 x 4, 그러면 Window의 개수는 2 x 2 x 2 = 8개가 된다.
- 그 다음 Layer에서는 (2, 2, 2) 만큼 Shift 시키고, Window의 개수는 3 x 3 x3 = 27이 된다
- 이런 방식은 Window의 개수가 늘어났다고 볼 수 이지만, Swin Transformer 의 방식처럼 Cyclic Shift를 이용해서 Masking Self-Attention으로 연산량을 유지 할 수 있다.(Window개수 8로 유지)
- Image Recongnition과 유사하게 3D Shift접근은 Kinetics 400/600, SSv2 같은 Action Recognition Task에서 효과(Temporal Modeling 잘됨) - 3D Relative Position Bias
-
- Architecture Variant
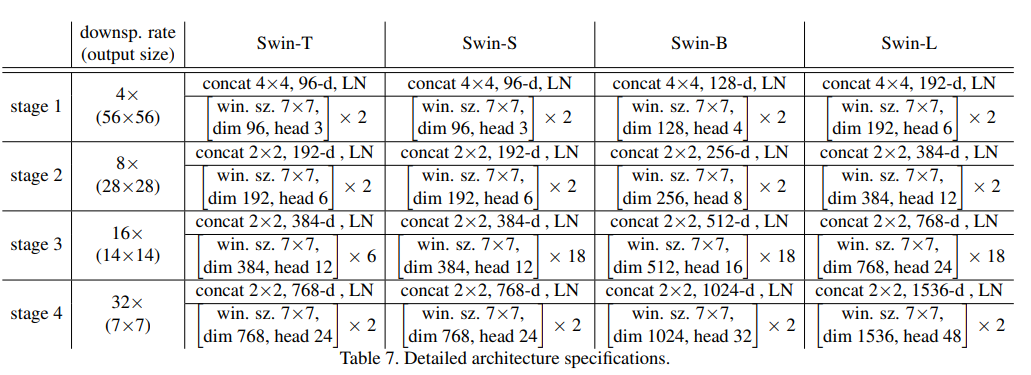
- 4개 Version의 Model Variant가 존재
- C는 Channel Number, Model Size과 Computational Complexity는 Base Model의 0.25, 0.5, 1, 2배
- Window size P = 8, M = 7, 각 Head의 Dimension은 d = 32가 되도록 조절, MLP Layer의 Expansion은 4

- Initialization From Pre-Trained Model
- Swin Transformer에서 구조를 가져오므로 Large Scale Dataset에서 Pretrain된 Image Model을 이용 가능
- Swin과 비교하여 Embedding Layer, Relative Position Bias만 다른 모양
- Relative Position Bias는 단순하게 2P-1번 복제하여 (2P-1, 2M-1, 2M-1)로 만듬
- Swin Transformer에서는 48C -> 96C (48C x 96C)로 바뀌는 Linear Embedding, 하지만 Swin Video에서는
96C -> 96C (96C x 96C)로 바뀜
- 이를 해결하기 위해 단순하게 Swin Transformer의 Weight를 두번 복제하고, 전체에 0.5곱해 평균과 분산을 유지
Experiments
- Dataset
- Human Action Recognition Kinetics-400(400 Class, 240k Train Dataset, 20k Valid Dataset)
- Human Action Recognition Kinetics-600(600 Class, 370k Train Dataset, 28.3k Valid Dataset)
- Temporal Modeling SSv2(174 Class, 168.9k Train Dataset, 24.7k Valid Dataset) - 4.2 Comparison To SOTA

- Kinetics-400
- Convolution Based, Transformer Based, Swin Based Model을 비교
- JFT로 Training ViViT보다 높은 성능을 보여줌(JFT는 ImageNet보다 훨씬 큰 Dataset)
- ViViT는 JFT로 Training하고 Fine Tuning할 경우 FLOPs가 너무 높지만 Swin-L은 ImageNet으로 Training하여 낮은 FLOPs, 높은 Accuracy를 보여 SOTA
- JFT로 Swin Transformer를 Training 하면 어떤 결과가 나올지 궁금

- Kinetics-600
- K600에서도 비슷한 결과를 얻음
- ImageNet-21k로 Pre Training한 Swin-L이 JFT로 Pre Training한 ViViT 보다 높은 성능
- 적은 FLOPs, Parameter가 장점 - Something-Something V2
- SSv2에서도 SOTA에 달성
- MViT-B 모델은 K-600으로 Pretraining 했지만, K-400으로 Pretraining한 Swin-B가 더 높은 성능
- 더 큰 Resolution 으로 시도하고 싶은데, 이것은 Future Work로 나둠 - 4.3 Ablation Study
- Different Designs for SpatioTemporal Attention
- 3개의 Major Desing을 이용해 Test 진행(Joint, Split, Factorized)
- Joint Version은 3D Window Based MSA Layer에서 Spatiotemporal Attention을 계산
- Split Version은 Spatial Swin Transformer위에다가 두개의 Temporal Transformer Layer를 추가, 이 방법은 ViViT에서 효과적(ViViT Facotrized Encoder방식)
- Factorized는 Swin Transformer의 각 Spatial Only MSA Layer 뒤에 Temporal 전용 MSA Layer 추가, 이는 TimeSformer에서 효과적인것으로 확인
- Factorized Version은 Pretrain Weight로 Temporal Layer를 초기화 하면 안좋으므로 Temporal Only Layer는 0으로 초기화
- Joint Version이 적절한 FLOPs, Parameter, Accuracy를 가짐
- Joint Version은 원래 ViT DeiT에서는 높은 Computational Cost가 높지만, Spatial Domain의 Locality의 효율성을 유지하기 떄문에 계산 비용이 줄어듬(Window Base Attention)
- Split Version은 잘 동작하지 않음, 해당 방식은 Pretrain에서 좋은 이점을 받기 어려움
- Factorized Version은 좋은 성능을 가지지만 더 많은 Parameter가 필요


- Temporal Dimension of 3D Tokens, Temporal Window Size
- Temporal 정보를 취할때 Temporal 축의 Window크기에 대한 연구를 진행함
- 일반적으로 Temproal Dimension이 클수록 Global하게 보는 것은 성능이 올라가지만, 느려짐(Window내의 3D Token이 증가)
- Temporal Dimension을 16으로 유지하고 Window Size의 Temporal를 줄일수록 성능은 낮아지고 연산은 가벼워짐(Window내의 3D Token 감소)
- 즉 Input Frame이 많을수록, Window의 사이즈가 클수록 성능은 좋아지지만, Token수가 늘어나므로 연산량이 무거워짐

- 3D Shifted Windows
- Temporal , Spatial 모두 Shift을 하는 것이 가장 좋게 나온것을 알 수 있다.

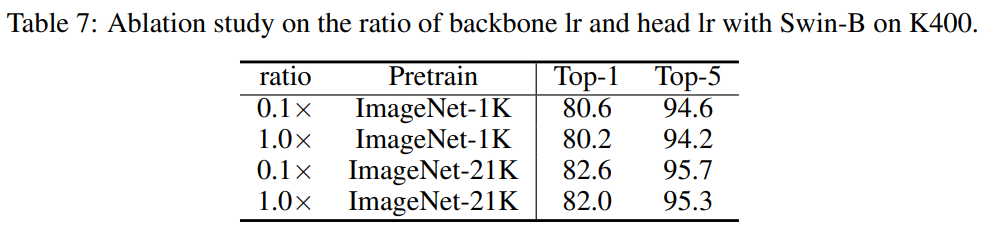
- Ratio of backbone/head learning rate
- Backbone, Head Learning Rate에 대한비율
- Backbone의 Learning Rate가 0.1배인 것이 가장 좋은 결과를 얻음
- 0.1로 설정하여 Backbone은 Pretrain된 Parameter를 천천히 잊고 Data가 새로운 Video Input에 Fitting되도록 함
- 좀더 일반화 효과가 좋음
- Initialization on linear embedding layer
- ViViT에서는 Center Initialization을 통해 큰 성능상승을 얻음
- Video Swin에서 2가지 Test를 진행했는데, 표 8처럼 Swin-Transformer 를 이용한 Video Model에서는 동일한 효과
- 그러므로 inflate 방식을 Default로 정함 - 3D relative position bias matrix
- 3D Relative Position Bias Matrix도 두개 방법을 선택함(Duplicate, Center)
- Linear Embedding Layer의 Center 초기화 방법과는 다르게 여러 Frame에 거쳐 Relative Position BIas를 마스킹해서 3D Relative Position Bias Matrix를 초기화
-비슷한 성능이 나와 Duplicate 방식을 선택하기로 결정

Conclusion
- 저자들은 Spatio Temporal Locality Inductive Bias를 기반으로하는 Video Recognition을 위한 Pure Transformer를제안
- 이 Model은 Image Recognition을 위해 만들어진 Swin Transformer를 기반으로 하였고, 강력한 Pretrain된 Image Model의 힘을 이용함
- K400, K600, SSv2에서 SOTA에달성